Das Ziel dieses Projektes ist es, aufgrund von historischen Daten von Patienten für neue Patienten das Risiko einer Angina Pectoris einzuschätzen. Die Art der Vorhersage ist eine binäre Klassifizierung (Zielvariable: 1 Risikopatient, 0 gesunder Patient), die Überwacht abläuft, das heißt, Historische Daten mit Labels sind bekannt und werden zum Lernen verwendet.
Die Beschreibung der Variablen war unklar und an manchen Stellen möglicherweise fehlerhaft. Eine Recherche zeigt, dass die Werte für cp wahrscheinlich folgende Bedeutung haben:
Value 0: asymptomatic Value 1: typical angina Value 2: atypical angina Value 3: non-anginal pain
Auch für thal gab es keine weitere Beschreibung, es ist wahrscheinlich, dass es für „Thallium Stress Test“ und hier für die Schädigung des Herzmuskels steht. Dafür sprechen die drei Kategorien ’normal‘, ‚fixed defect‘ und ‚reversable defect‘, die in der Beschreibung des Datensatzes zu finden waren.
target 1 or 0 (Zielvariable, Risiko ja (1) oder nein (0))
Methode
Der Datensatz wird überprüft und erstes Datamining wird durchgeführt. Die Eigenschaften des Datensatzes werden visualisiert. Der Datensatz wird für das Machine Learning vorbereitet. Im Feature Engineering werden die Vorhersage-Variablen manipuliert, um die Aussagekraft zu verstärken bzw. schwache Vorhersagevariablen zu entfernen. Verschiedene Machine Learning Algorithmen werden am Datensatz getestet, die besten werden ausgewählt, um weiter verfeinert zu werden. Es werden verschiedene Kombinationen von Features und Hyperparametern der Algorithmen gestestet, um die besten Vorhersagen treffen zu können.
Ein erster Überblick über den Datensatz hilft, die Informationen einzuordnen und eine Strategie für die Manipulation und Bereinigung der Daten zu entwerfen.
Findings: Alle Variablen sind numerisch und konsistent, es fehlen keine Werte, die Verteilung der Zielvariablen ist ausgeglichen, es gibt fast genau so viele Werte in Target mit 0 wie mit 1.
Feature Engineering
Feature Engineering ist einer der wichtigsten Schritte im Aufbau eines Machine Learning Models. Es gibt verschiedene Ansätze, neue Features zu kontruieren und unwichtige Features zu entfernen (Dimensionality Reduction). An dieser Stelle soll folgender Ansatz getestet werden: Das Hinzufügen von Polynomial Features.
Da es ursprünglich nur 13 Features sind, wird eine Dimensionality Reduction nicht in Betracht gezogen. Auch mit 91 Features ist die Rechenzeit für Hyperparameter Tuning sehr schnell.
Modeling
Die Daten werden in einen Train und einen Test-Datensatz aufgeteilt und skaliert. Im Anschluss werden mehrere Algorithmen auf einmal getestet und diejenigen, die auf dem Testset am besten performt haben, werden gewählt, um weiter optimiert zu werden.
Metrik
Hier wird der Accuracy-Score und Recall als Metriken verwendet. Der Accuracy-Score kann eine allgemeine Aussage über die Güte des Models machen, wohingegen Recall verwendet wird, wenn es wichtig ist, alle positiven Fälle zu finden und so wenige wie möglich falsch zu klassifizieren (False Negative)
Bei Patienten mit einer möglichen Angina ist es sehr wichtig, jedes Risiko auszuschließen. Lieber testet man einen Patienten mit einem geringen Risiko noch einmal, als einen Patientien mit einem hohen Risiko nach Hause zu schicken.Der Recall kann durch eine Veränderung der Entscheidungsgrenze beeinflusst werden.
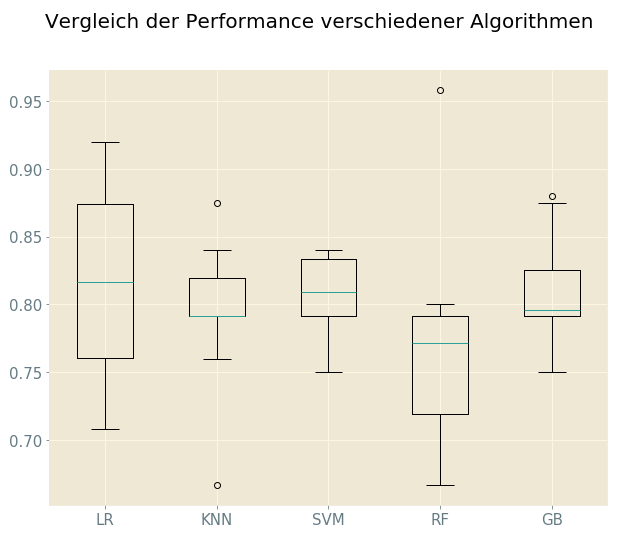
Vergleich und Auswahl von Algorithmen
Im Allgemeinen ist es so, dass kein Algorithmus immer der Beste für eine bestimmte Problemart ist (No Free Lunch Theorem). Daher werden mehrere Algorithmen, die zur Problemstellung passen, getestet. Dann wird derjenige Algorithmus, der am besten performt, ausgewählt, um weiter optimiert zu werden.
Folgende Algorithmen werden getestet:
Logistic Regression
Random Forest Classifier (Ensemble Methode)
Gradient Boosting Classifier (Ensemble Methode)
Support Vector Classifier
K-nearest Neighbors Classifier
Auswahl
Zur weiteren Evaluierung werden Logistic Regressoin, Gradient Boosting und der Support Vector Classifier ausgewählt.
Logistic Regression
Für diesen Algorithmus ist es wichtig, die Daten vor dem Lernen zu Standardisieren, um optimale Ergebnisse zu erzielen. Dies wird mit Hilfe des Sklearn Standard Scaler gemacht. Das Fitten geschieht ausschließlich auf dem x_train Satz, dann werden x_train und x_test transformiert.
Weiteres Vorgehen:
Baseline erstellen
Hyperparameter Tuning
Test mit Polynomial Datensatz
Anpassung des Thresholds für eine optimale Sensitivity
Ergebnis Logistic Regression
Es konnte beim Hyperparameter Tuning ein bester Wert für C, den Parameter für die Regularisierung, festgestellt werden. Die Verwendung des Polynomial Datensatz konnte keine weiteren Verbesserungen der Vorhersagen produzieren. Der beste Threshold für diese Art der Problemstellung, bei der es wichtig war, den Recall so weit wie möglich zu erhöhen, ohne zu viele False Positives zu erhalten, lag bei 0.5.
Gradient Boosting
Ensemble Learning für binäre Klassifikation. Schwache Lerner sind Entscheidungsbäume. Die Bäume werden nacheinander kreiert, nach jedem Baum werden die Variablen neu gewichtet und der nächste Baum lernt aus den Fehlern des vorherigen Baumes.
Hyperparameter Tuning und Test mit Polynomial Features
Baseline
Der Accuracy-Score mit den voreingestellten Hyperparametern (Defaults) liegt bei 77%. Mit Grid Search wird versucht, die besten Hyperparameter für dieses Model zu finden, in dem alle Kombinationen der gegebenen Hyperparameter getestet werden. Der Test wird als Kreuzvalidierung durchgeführt, als Metrik wird der Accuracy-Score verwendet.
Beste Hyperparameter:
learning_rate: 0.05
max_depth: 8
max_features: ’sqrt‘
n_estimators: 200
subsample: 0.5
Der Accuracy_Score auf dem Testset liefert mit diesen Hyperparametern einen Wert von 0.88!
Test mit dem Polynomial Feature Set
Das Model mit den Polynomial und Interaction Features performt mit den default Hyperparametern besser, mit den optimalen Hyperparametern schlechter als der Original Datensatz.
Fazit
Das Hyperparameter Tuning und Feature Engineering konnten in Einzelfällen Verbesserungen des Accuracy-Scores zeigen, jedoch nicht in Kombination miteinander. Hier wären weitere Experimente notwendig, um die beste Kombination aus Features und Hyperparametern zu finden. Beim Recall performt das Model mit Gradient Boosting schlechter als mit Logistic Regression, daher wird das Model nicht weiter untersucht.
Support Vector Classifier
Kernel Methode mit Kernel Trick. Transformiere Daten in eine andere Dimension, die eine klare Grenze zwischen den Klassen zeigt. Die wichtigsten Parameter sind C, Gamma und der Kernel. Beschreibung bei Scikit-Learn: https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
Ergebnisse
Mit dem Model aus dem Algorithmus Support Vector Machines und dem Datensatz aus dem Feature Engineering gibt es die besten Vorhersagen. Der Einsatz des Polynomial Datensatz hat mit den default Einstellungen die Accuracy auf 85% verbessert, die Kombination aus besten Hyperparametern und Feature Engineering konnte das Ergebnis von 54% Accuracy auf 90% verbessern!
Zusammenfassung
In diesem Projekt wurden die Algorithmen Logistic Regression, Gradient Boosting und Support Vector Classifier getestet. Es gab zwei Feature Sets, den Original-Datensatz und ein Datensatz mit Polynomial und Interaction Features.
Bestes Model
Mit dem Model aus dem Algorithmus Support Vector Machines und dem Datensatz aus dem Feature Engineering gibt es die besten Vorhersagen.
Höchster Accuracy-Score
Support Vector Machines: 90%
Logistic Regression: 88%
Gradient Boosting: 88%
Bester Recall
Logistic Regression: 0.91
Support Vector Machines: 0,89
Gradient Boosting: 0.78
Verbesserungsmöglichkeiten
Mehr Daten, mehr Instanzen, mehr Features
In der Logistic Regression wurden drei Patienten nicht als Risikopatienten erkannt, hier würde sich eine weitere Analyse lohnen, warum diese als gesund klassifiziert worden waren. Mit den Erkenntnissen könnte die Vorhersage weiter verbessert werden, in dem beispielsweise neue Features erstellt werden.