
Photo by Mark Minge on Pixabay
Vorhersage der Verbreitung des West Nil Virus in Chicago
Hintergrund
Das West-Nil-Fieber ist eine Virusinfektion, die durch Moskitos übertragen wird. Die hauptsächlichen Wirte des Virus sind Vögel, es kann aber auch Säugetiere infizieren. Für einen gesunden Menschen sind die Symptome mild, vergleichbar einer Grippe, es gibt allerdings auch schwere Verläufe, die tödlich enden können. Aus diesem Grund ist es notwendig, die Verbreitung des Virus im Auge zu behalten. In Chicago wurde das Virus erstmals 2002 bei Menschen diagnostiziert, woraufhin ein Überwachungsprogramm ins Leben gerufen wurde, das bis heute läuft.
Ziel
Jedes Jahr werden von Mai bis Ende Oktober Fallen im Stadtgbebiet von Chicago, Illinois, aufgestellt. Montags bis Mittwochs werden die gefangenen Stechmücken eingesammelt. Die Anzahl der Mücken pro Fallen, deren Spezies und ob das WNV in der Kohorte vorhanden ist, oder nicht, werden bestimmt.
Ziel des Projektes ist es, vorherzusagen, wann und wo das Virus als nächstes auftritt.
Art der Vorhersage Binäre Klassifikation und kann dem Überwachtes Lernen zugeornet werden, da anhand von historischen Daten und gegebenen Zielwerten gelernt wird.
Datensatz
Der Datensatz stammt aus einem kaggle Wettbewerb (Link unter Quellen). Es wurden drei Datensätze angefertig, in diesen finden sich Werte aus Beobachtungen über den Zeitraum von drei Jahren. Definitionen und Erklärungen zu den Variablen sind unter dem angegebenen Link zu finden.
- Train: Daten über Fallen und gefangene Moskitos und der Präsenz des Virus
- Weather: Wetterdaten aus zwei Wetterstationen in Chicago
- Spray: Daten über das Ausbringen von Insektenspray
Methode
Der Datensatz wird überprüft und erstes Datamining wird durchgeführt. Die Eigenschaften des Datensatzes werden visualisiert. Der Datensatz wird für das Machine Learning vorbereitet. Im Feature Engineering werden die Vorhersage-Variablen manipuliert, um die Aussagekraft zu verstärken bzw. schwache Vorhersagevariablen zu entfernen. Verschiedene Machine Learning Algorithmen werden am Datensatz getestet, die besten werden ausgewählt, um weiter verfeinert zu werden. Es werden verschiedene Kombinationen von Features und Hyperparametern der Algorithmen gestestet, um die besten Vorhersagen treffen zu können.
Als Metrik wird der AUC verwendet, die Fläche unter der ROC Curve.
Tools
- Distribution: Anaconda
- Applikation: Jupyter Notebook
- Sprache: Python
- Pandas: Vorbereiten der Daten und Explorative Datenanalyse
- Scikit Learn: Machine Learning Algorithmen und Techniken
- Visualisierungen wurden mit Seaborn, Matplotlib und mit plotly erstellt
- Resampling: imbalanced-learn
Data Cleaning und Exploration
In jedem Machine Learning Projekt ist dieser Abschnitt sehr wichtig. Hier lerne ich die Daten kennen, verstehe die Zusammenhänge zwischen den Variablen und der Zielvariablen. Visualisierungen helfen, die Daten besser zu verstehen.
Gleichzeitig wird der Datensatz auf Fehler hin untersucht. Fehlen Werte? Wurde den Variablen das richtige Format zugewiesen? Gibt es vielleicht Tippfehler oder andere Inkonsistenzen?
Datensatz Weather: Exploration, Cleaning und Feature Engineering
Im Datensatz finden sich die Daten aus zwei Wetterstationen:
Station 1: CHICAGO O’HARE INTERNATIONAL AIRPORT Lat: 41.995 Lon: -87.933 Elev: 662 ft. above sea level
Station 2: CHICAGO MIDWAY INTL ARPT Lat: 41.786 Lon: -87.752 Elev: 612 ft. above sea level
Folgende Variablen sind im Datensatz enthalten:
‚Station‘, ‚Date‘, ‚Tmax‘, ‚Tmin‘, ‚Tavg‘, ‚Depart‘, ‚DewPoint‘, ‚WetBulb‘, ‚Heat‘, ‚Cool‘, ‚Sunrise‘, ‚Sunset‘, ‚CodeSum‘, ‚Depth‘,’Water1′, ‚SnowFall‘, ‚PrecipTotal‘, ‚StnPressure‘, ‚SeaLevel‘, ‚ResultSpeed‘, ‚ResultDir‘, ‚AvgSpeed‘
Datentypen und fehlende Werte:
Viele der Spalten haben unpassende Datentypen. Sie sollten keine ‚object‘ sein, sondern numerisch. Object wurde automatisch zugewiesen, da sich nicht nur Zahlen in den Spalten befinden. Fehlenden Werte wurden hier durch verschiedene Strings dargestellt sind (M, T…). Um die richtigen Datentypen zuweisen zu können, müssen zuerst die Strings umgewandelt werden.
Bei den Features Sunrise, Sunset und Depart fehlen die Hälfte der Werte, dies liegt daran, dass sie nur in einer der beiden Station dokumentiert wurden. Diese Werte können einfach übertragen werden.
Die fehlenden Werte für Tavg, der mittleren Temperatur, können aus den Temperaturen berechnet werden.
SnowFall, Depth, CodeSum und Water1 fügen dem Datensatz keine relevanten Informationen hinzu und werden entfernt.
Wichtige Features aus wissenschaftlichen Grundlagen (Quellen: Domain-Wissen)
Wenn es geregnet hat, werden Zeitversetzt mehr Stechmücken schlüpfen. Wenn es sehr windig war, fliegen die Mücken weniger und pflanzen sich vielleicht auch weniger fort. Wenn es warm, feucht, bedeckt und windstill ist, ist die Aktivität der Mücken am höchsten und die Fortpflanzungsrate steigt.
- Temperatur (Tmin, Tmax, Tavg): Je höher, desto besser für die Viren (bis 30°C, danach kehrt sich der Effekt um)
- Niederschlag (PrecipTotal): Im Allgemeinen kann gesagt werden, dass höhere Niederschläge aufgrund der größeren Menge an Brutstätten mehr Stechmücken bedeuten. Aber auch Dürre kann sich unter bestimmten Umständen als vorteilshaft erweisen, vor allem für Culex Pipiens, die am häufigsten vorkommende Spezies in Chicago.
- Es kann auch sein, dass auf sehr verregnete Jahre Jahre mit wenigen Steckmücken folgen.
- Relative Feuchtigkeit (Wet Bulb und Dew Point): Kein so guter Predictor wie Lufttemperatur, es kann jedoch Korrelationen geben.
- Windstärke
Konstruierte Features
- Anzahl der Tage in Folge bis zum Zeitpunkt der Beobachtung mit Temperaturen 25<Tavg<30° C ( 77- 86°Fahrenheit)
- Gesamtregenfall für die Periode Mai bis Oktober für jedes Jahr (wird für das folgende Jahr verwendet)
- Tage seit letztem Regenfall (Lag) 3 Tage
- Tage seit letztem Regenfall (Lag) 8 Tage
- Tage seit letztem Regenfall (Lag) 15 Tage
- Wind-Lag (3, 8, 15)
- Länge des Tages ersetzt Sonnenaufgang und Untergang (ist eine Vorhersage)
Datensatz Train: Exploration, Cleaning und Feature Engineering
Dies ist der Haupt-Datensatz, in dem sich Informationen über die Orte der Fallen und der gefangenen Moskitos befinden.
Die Variablen:
- ‚Date‘, Datum der Beobachtung
- ‚Address‘, Adresse der Falle
- ‚Species‘, Unterart des Moskitos
- ‚Block‘, Adresse der Falle
- ‚Street‘, Adresse der Falle
- ‚Trap‘, ID der Falle
- ‚AddressNumberAndStreet‘, Adresse der Falle
- ‚Latitude‘, Breitengrad des Aufstellungsortes der Falle
- ‚Longitude‘, Längengrad des Aufstellungsortes der Falle
- ‚AddressAccuracy‘, Genauigkeit der automatisch ermittelten Adresse
- ‚NumMosquitos‘, Anzahl der Moskitos
- ‚WnvPresent‘, Präsenz des Virus in der Kohorte
Kombination der Datensätze Train und Weather
Die Datensätze werden über das Datum als Schlüsselvariable zusammengefügt. Im Anschluss wird das Datum aufgeteilt in year, month und day of year. Die Variable „Trap“ wird entfernt, hier reicht als Information die Lage (Longitude/Latitude) der Fallen. Es wird ein Flag für Spray gesetzt. Diese Informationen stammen aus einem dritten Datensatz, Spray, der sich bei kaggle findet.
Vorbereitung der Daten für das Modeling
Da zuerst mehrere Algorithmen getestet werden sollen, ist es sinnvoll, den Datensatz auszugleichen und zu normalisieren, da manche Algorithmen sonst nicht korrekt aus den Daten lernen können. Je nachdem, auf welchen Algorithmus im Anschluss die Wahl fällt, kann dann der Original-Datensatz verwendet werden.
Train- und Testset
Ein Test Set wird zu Anfang erstellt und dann beiseitegelegt. Es wird am Ende, wenn das Model kreiert wurde, verwendet, um die Performance des Models zu evaluieren. Auf keinen Fall sollten die Train Daten zum Testen oder andersherum verwendet werden, da das Model hier nicht lernen würde, zu generalisieren. Die Ergebnisse wäre sehr gut, aber das Model wäre overfitted und würde bei neuen Daten sehr schlechte Ergebnisse zeigen.
Umgang mit Class Imbalance
Wenn es sehr viel mehr Instanzen einer Klasse gibt, als von der anderen, ist der Datensatz unausgeglichen (Class Imbalance). Für die meisten Machine Learning Algorithmen ist es so schwer, die unterrepräsentierte Klasse zu lernen. Es gibt mehrere Möglichkeiten, dem Problem zu begegnen:
- Mehr Daten sammeln, was die beste Alternative ist, allerdings leider nicht immer möglich.
- Oversampling: Es werden neue Instanzen der Klasse, die sich in der Minorität befindet, kreiert
- Undersampling: Von der Mehrheitsklasse werden Instanzen gelöscht, um einen ausgeglicheneren Datensatz zu erhalten.
- Manche Algorithmen haben einen Hyperparameter, der entsprechend gesetzt werden kann, wenn der Datensatz unausgeglichen ist.
Das Resampling wird nur mit dem Train Datensatz gemacht, damit die Maschine Gelegenheit hat, alle Klassen zu lernen. Der Test Datensatz bleibt unberührt. Das Aufteilen des Datensatzes in Trainings und Test-Datensätze und bei der Kreuzvalidierung soll stratifiziert erfolgen, damit alle Klassen in jedem Datensatz bzw. Fold repräsentiert sind.
Hier verwende ich SMOTE für das Oversampling.
Feature Transformation
Die Daten werden mit dem StandardScaler aus Scikit-Learn normalisiert.
Damit werden alle Features jeweils so transformiert, dass sie normalverteilt sind, der Mittelweirt bei 0 liegt und die Standardabweichung = 1 ist.
Modeling
Metrik
Hier wird der F1 Score als Metrik verwendet. Er ist eine Kombination aus Precision und Recall und ideal für Probleme, bei denen der Datensatz unausgeglichen ist.
F1 = 2 * (precision * recall) / (precision + recall)
Bei der Berechnung des Mittelwertes in der Kreuzvalidierung für die Auswahl des Algorithmus wird als average „micro“ oder „weighted“ verwendet, weil hier die Klassen entsprechend gewichtet werden.
Vergleich und Auswahl von Algorithmen
Im Allgemeinen ist es so, dass kein Algorithmus immer der Beste für eine bestimmte Problemart ist (No Free Lunch Theorem). Daher werden mehrere Algorithmen, die zur Problemstellung passen, getestet. Dann wird derjenige Algorithmus, der am besten performt, ausgewählt, um weiter optimiert zu werden.
Folgende Algorithmen werden getestet:
- Logistic Regression
- Random Forest Classifier (Ensemble Methode)
- Gradient Boosting Classifier (Ensemble Methode)
- Support Vector Classifier
- K-nearest Neighbors Classifier
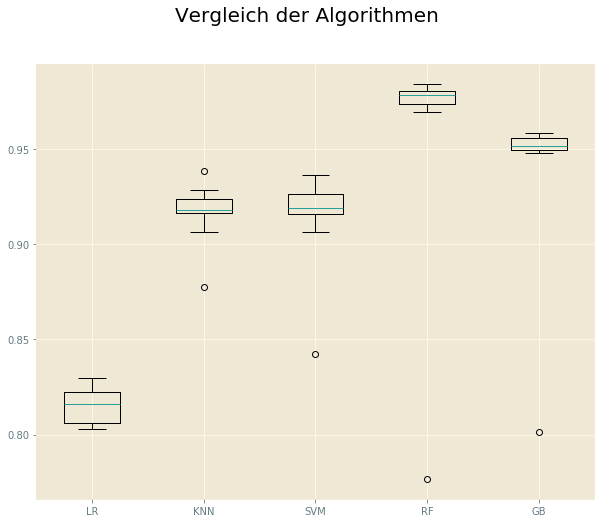
Auswahl
Das Ensemble Random Forest Classifier schneidet im Performance Test mit diesem Datensatz am besten ab und wird gewählt, um weiter optimiert zu werden.
Optimierung des Models
Vorbereitung der Daten, Hyperparameter Tuning und ….xxxxxxxxxx
Zusammenfassung
Hier eine kurze Zusammenfassung der Ergebnisse.
Folgende Schritte wurden im Projekt unternommen
- Beide Datensätze wurden bereinigt und erforscht
- Feature Engineering wurde an beiden Datensätzen durchgeführt
- Beide Datensätze wurden kombiniert
- Mehrere Algorithmen wurden getestet und Random Forest gewählt
- Das gewählte Model wurde optimiert
Bestes Model
Der beste Algorithmus war mit Abstand das Ensemble aus Entscheidungsbäumen. Es hat sich außerdem gezeigt, dass das Feature Engineering zur Verbesserung der Performance beigetragen hat. Dennoch sind die Ergebnisse leider nur marginal besser, als die Baseline. Daraus folgt, dass es sinnvoll sein kann, eine neue Studie mit verbesserter Datenaufnahme durchzuführen.
Gute Indikatoren waren:
- Anzahl der Moskitos in einer Falle
- Der Breitengrad/ Lägengrad
- Flag für Spray
- Sonnenaufgang
- Entfernung zur Falle T115, T900 und T138, wo das Virus in der Saison zuerst entdeckt worden war, also eine mögliche Quelle darstellt
Länge des Tages
Verbesserungsmöglichkeiten
Informationen, die hier nicht berücksichtigt werden, aber für eine bessere Analyse zu einem späteren Zeitpunkt miteinbezogen werden könnten:
- Culex Pipiens fühlt sich in urbanen Landschaften sehr wohl; die größten Ausbrüche des West-Nil-Virus in Europa waren in Städten.
- Die Vogelpopulation (Zugvögel) spielt eine große Rolle, da sie die Primären Wirte für das West-Nil-Virus sind.
- Je mehr Transporte (Reisen, Güter) stattfinden, desto besser kann sich das Virus verbreiten
- Dürren
- Überschwemmungen
- Temperaturen im Winter
- Nähe zu Parks mit Wasser
- Nähe zu Altreifen-Sammlungen
- Nähe zu Landwirtschaftlichen Flächen
- Populationsdichte der Stadtteile miteinbeziehen
- Vogeldichte
- Anzahl von Brückenvektoren in Fallen (= Moskitos, die Vögel und Menschen stechen)
- Windrichtung
- Druckunterschiede zwischen verschiedenen Gegenden
Weitere Erkenntnisse
Es geht aus den vorliegenden Daten nicht hervor, wie sich das Ausbringen von Gift auf die Population der Moskitos auswirkt, hier könnten weitere Studien sinnvoll sein.