Um Armut weltweit besiegen zu können, werden gute Modelle gebraucht, die vorhersagen können, wie sicher Menschen vor Armut sind und an welcher Stelle Hilfe am nötigsten ist.
Um sicherzustellen, dass soziale Wohlfahrtsprogramme an der richtigen Stelle Hilfe leisten können, gibt es den Proxy Means Test, eine Bedürftigkeitsprüfung. Dies ist eine Feststellung, ob eine Person oder eine Familie Anspruch auf staatliche Unterstützung hat, basierend darauf, ob die Person oder die Familie die Mittel besitzt, auf diese Hilfe zu verzichten. In diesem Fall sind die betrachteten Attribute Eigenschaften des Hauses, in dem eine Familie lebt, zum Beispiel der Zustand und das Material von Wänden und Böden. Die vorliegenden Daten wurden von der interamerikanischen Entwicklungsbank zur Verfügung gestellt, die Ergebnisse sollen dazu dienen, weltweit die Hilfestellung bei bedürftigen Familien zu verbessern.
Entwicklung eines Models, das zur Identifikation von Haushalten und Familien, die ein Recht auf staatliche Unterstützung haben, verwendet werden kann.
Ziel dabei ist die Vorhersage eines Armutslevels, basierend auf Charakteristika eines Haushaltes.
Datensatz
Der Datensatz beinhaltet einen repräsentativen Ausschnitt von Haushalten in Costa Rica. Es gibt Attribute zu den Haushalten im Allgemeinen und zu den einzelnen Personen eines jeden Haushaltes, so wie die Bildungsstufe, das Alter oder das Geschlecht.
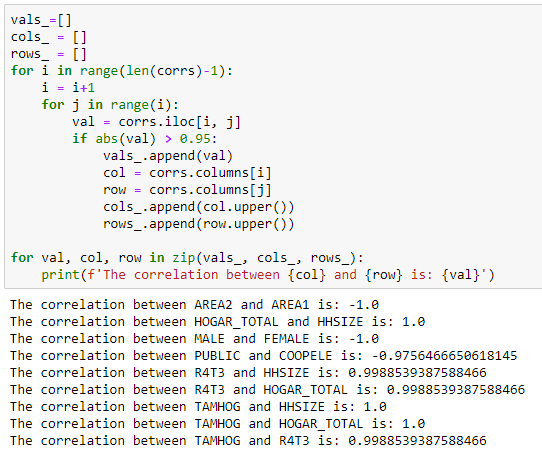
Code, um aus der Korrelationsmatrix alle Werte, die über 0.95 liegen, zu extrahieren. Jeden Wert nur einmal anzeigen, also nur alle Werte, die über der Diagonalen liegen, extrahieren und vergleichen.
Da zuerst mehrere Algorithmen getestet werden sollen, ist es sinnvoll, den Datensatz auszugleichen und zu normalisieren, da manche Algorithmen sonst nicht korrekt aus den Daten lernen können. Je nachdem, auf welchen Algorithmus im Anschluss die Wahl fällt, kann dann der Original-Datensatz verwendet werden.
Train- und Testset
Ein Test Set wird zu Anfang erstellt und dann beiseitegelegt. Es wird am Ende, wenn das Model kreiert wurde, verwendet, um die Performance des Models zu evaluieren. Auf keinen Fall sollten die Train Daten zum Testen oder andersherum verwendet werden, da das Model hier nicht lernen würde, zu generalisieren. Die Ergebnisse wäre sehr gut, aber das Model wäre overfitted und würde bei neuen Daten sehr schlechte Ergebnisse zeigen.
Umgang mit Class Imbalance
Wir haben eine Class Imbalance in einem Multi-Class-Problem vorliegen. Daher wird mit SMOTE oversampled, so dass eine Gleichverteilung der Zielvariablen vorliegt. Das Oversampling wird nur für den Trainings-Datensatz durchgeführt.
Feature Transformation
Die Daten werden mit dem StandardScaler aus Scikit-Learn normalisiert.
Damit werden alle Features jeweils so transformiert, dass sie normalverteilt sind, der Mittelweirt bei 0 liegt und die Standardabweichung = 1 ist.
Modeling
Metrik
Hier wird der F1 Score als Metrik verwendet. Er ist eine Kombination aus Precision und Recall und ideal für Probleme, bei denen der Datensatz unausgeglichen ist.
Bei der Berechnung des Mittelwertes in der Kreuzvalidierung für die Auswahl des Algorithmus wird als average „micro“ oder „weighted“ verwendet, weil hier die Klassen entsprechend gewichtet werden, was bei einer Class Imbalance wichtig ist.
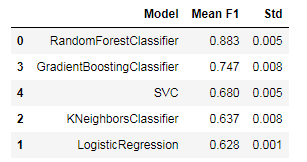
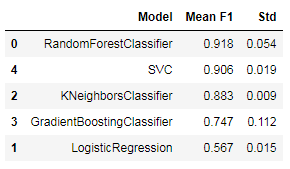
Vergleich und Auswahl von Algorithmen
Getestet werden:
Logistic Regression: Kann für multiclass Aufgaben verwendet werden mit Parametern solver=’lbfgs‘, multi_class=’multinomial‘
Random Forest Classifier: Ensemble aus Entscheidungsbäumen
KNeighbors Classifier
Support Vector Classifier
Gradient Boosting Classifier
Ergebnisse für den F1-Score und Standardabweichung ohne Oversampling und skalieren
Ergebnisse für den F1-Score und Standardabweichung mit Oversampling und skalieren
Auswahl
Der Random Forest Algorithmus zeigt die besten Ergebnisse, daher wird dieser nun weiter verwendet und optimiert.
Optimierung des Models
Testen verschiedener Datensätze
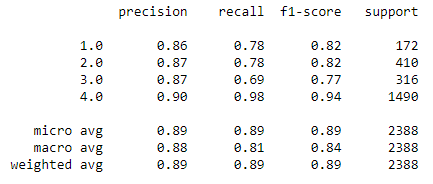
Random Forest mit default Parametern und mit Originaldatensatz
Weighted Random Forest mit Originaldatensatz
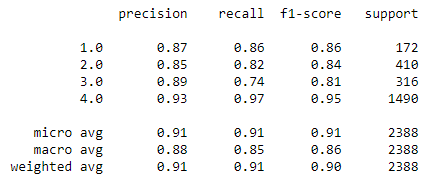
Random Forest mit default Parametern und oversampling des Train Datensatzes
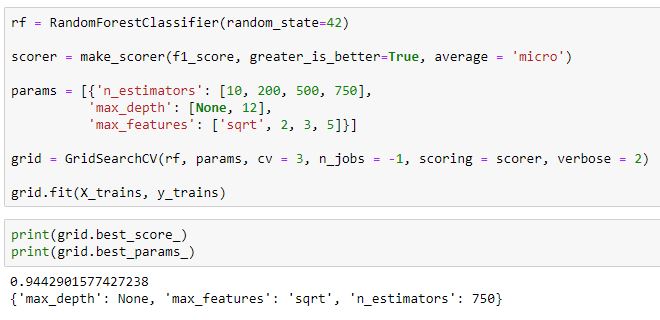
Beste Hyperparameter
Mit Grid Search werden die besten Hyperparameter für dieses Model gefunden.
Der Train Datensatz ist weiterhin oversampled, jedoch nicht skaliert. Mit diesen Parametern sind die Ergebnisse wie folgt:
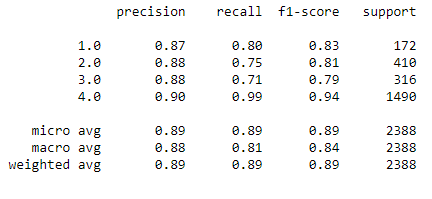
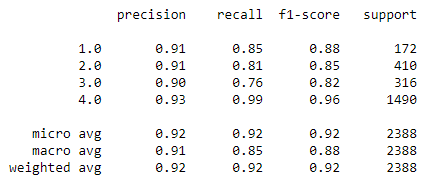
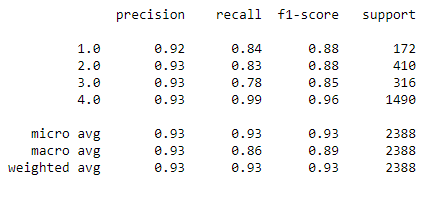
Ergebnisse des besten Models
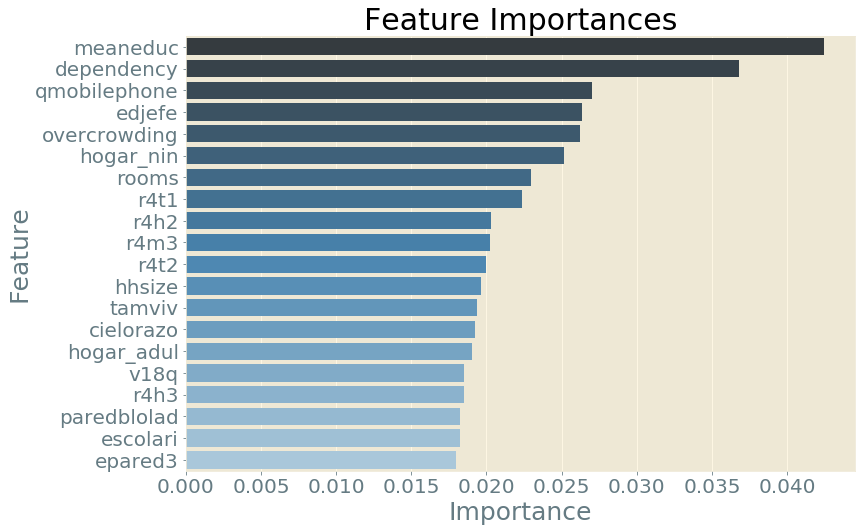
Wichtigste Features
Ergebnisse nach Recursive Feature Elimination
Neuer Datensatz, in dem nur die wichtigsten Features behalten werden, wird mit dem besten Model getestet. Es zeigt sich, dass der F1-Score so weiter verbessert werden konnte.
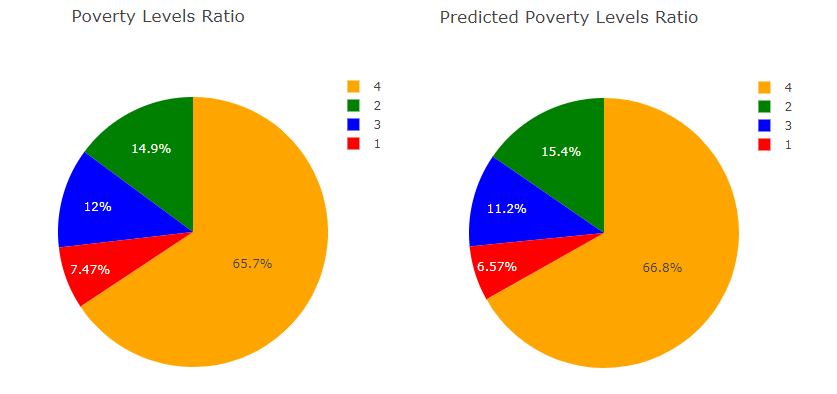
Verteilung der Variablen im Datensatz und Verteilung der vorhergesagten Variablen
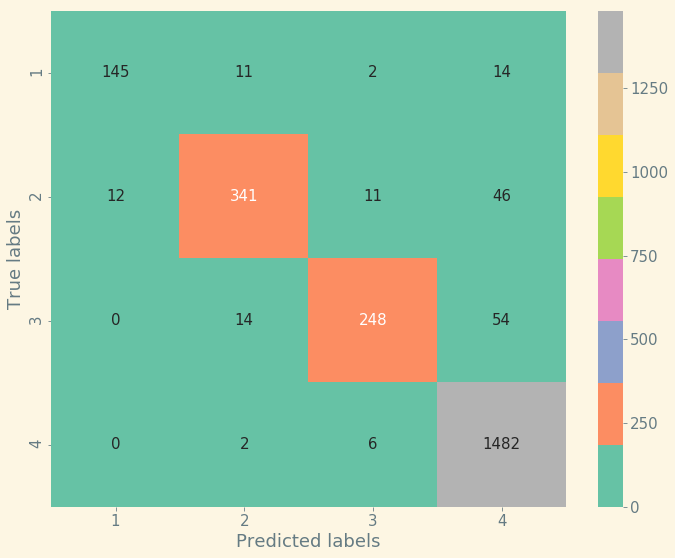
Confusion Matrix
Folgende Schritte wurden im Projekt unternommen
Bereinigung der Daten und Exploration
Feature Engineering
Vergleich und Auswahl von Algorithmen
Hyperparameter Tuning des besten Algorithmus
Testen verschiedener Feature-Sets
Das beste Model auf dem Test-Set evaluieren
Bestes Model
Random Forest Classifier, Datensatz mit X_train oversampled mit SMOTE und Feature Selection mit Recursive Feature Elimination