Da neue Kunden für ein Unternehmen zu gewinnen sehr teuer ist, als Bestandskunden zu erhalten, ist es von Interesse, Wege zu finden, Kunden vom Kündigen ihres Vertrages (churn) abzuhalten. Dafür ist eine gute Abschätzung, welcher Kunde in Gefahr ist, zu kündigen, sehr wichtig, um rechtzeitig aktiv werden zu können. Dies ist ein Model, das vorhersagen soll, welcher Kunden ein hohes Churn-Risiko haben. Art der Vorhersage: Binäre Klassifizierung (1 kündigt, 0 bleibt), überwacht (Historische Daten mit Labels sind bekannt und werden zum Lernen verwendet)
Datensatz
Der Datensatz besteht aus 7043 Observationen und 20 Features, hinzu kommt 1 Label, die Zielvariable. Die Features beschreiben Services, die der Kunde in der Vergangenheit verwendet hat, und beinhaltet darüber hinaus Kontoinformationen und Demographische Daten des Kunden. Die Daten stammen aus einem kaggle Wettbewerb.
Wichtige Features: Tenure: Zeit, die eine Person Kunde bleibt. Dieser Wert soll optimiert werden. Churn: Ist die Person noch Kunde oder hat sie gekündigt
Erklärung der Variablen
customerID: Customer ID
gender: Whether the customer is a male or a female
SeniorCitizen: Whether the customer is a senior citizen or not (1, 0)
Partner: Whether the customer has a partner or not (Yes, No)
Dependents: Whether the customer has dependents or not (Yes, No)
tenure: Number of months the customer has stayed with the company
PhoneService: Whether the customer has a phone service or not (Yes, No)
MultipleLines: Whether the customer has multiple lines or not (Yes, No, No phone service)
InternetService: Customer’s internet service provider (DSL, Fiber optic, No)
OnlineSecurity: Whether the customer has online security or not (Yes, No, No internet service)
OnlineBackup: Whether the customer has online backup or not (Yes, No, No internet service)
DeviceProtection: Whether the customer has device protection or not (Yes, No, No internet service)
TechSupport: Whether the customer has tech support or not (Yes, No, No internet service)
StreamingTV: Whether the customer has streaming TV or not (Yes, No, No internet service)
StreamingMovies: Whether the customer has streaming movies or not (Yes, No, No internet service)
Contract: The contract term of the customer (Month-to-month, One year, Two year)
PaperlessBilling: Whether the customer has paperless billing or not (Yes, No)
PaymentMethod: The customer’s payment method (Electronic check, Mailed check, Bank transfer (automatic), Credit card (automatic))
MonthlyCharges: The amount charged to the customer monthly
TotalCharges: The total amount charged to the customer
Churn: Whether the customer churned or not (Yes or No)
Methode
Der Datensatz wird überprüft und erstes Datamining wird durchgeführt. Die Eigenschaften des Datensatzes werden visualisiert. Der Datensatz wird für das Machine Learning vorbereitet. Im Feature Engineering werden die Vorhersage-Variablen manipuliert, um die Aussagekraft zu verstärken bzw. schwache Vorhersagevariablen zu entfernen. Verschiedene Machine Learning Algorithmen werden am Datensatz getestet, die besten werden ausgewählt, um weiter verfeinert zu werden. Es werden verschiedene Kombinationen von Features und Parametern der Algorithmen gestestet, um die besten Vorhersagen zu finden.
Ziel der Exploration ist es, den Datensatz zu beschreiben und ein Gefühl für Beziehungen und Zusammenhänge zu bekommen, die später im Model eine Rolle spielen können. Die Daten sollten währenddessen immer auf Konsistenz und Korrektheit überprüft werden (Garbage in, Garbage out)
Feature Engineering
Im Feature Engineering wurden kollineare Features entfernt und mehrere Datensätze mit Polynomial und Interaction Features als auch Datensätze mit Log-Transformationen getestet. Mit Random Forest wurden die wichtigsten Features bestimmt und ein neuer Datensatz nur mit diesen getestet. Leider waren die Ergebnisse wenig erfolgsversprechend, daher wurde im Folgenden immer mit dem Originalsatz gearbeitet.
Modeling
Metrik
Da es sich um eine assymetrischen Datensatz handelt, scheidet Accuracy als Metrik aus (Accuracy Paradox).
Wichtig bei dieser Klassifizierung ist es, mögliche Kündigungen rechtzeitig zu erkennen und zu verhindern. Daher kann es sinnvoll sein, etwas mehr False Positives zu identifizieren, als zu viele False Negatives zu haben (Erhöhung von Recall). Daher werden Precision/Recall und der F1-Score als Metriken verwendet.
Testen des Model mit vier Algorithmen
Laut dieser Studie sind dies die besten Klassifizierer: Random Forest, Support Vector Machines, Boosting Ensembles und Neuronale Netze. Allerdings: No free Lunch! In diesem Projekt werden zusätzlich Logistic Regression, K-Nearest Neighbors getestet. Da Neuronale Netze schwierig zu interpretieren sind, werden sie in diesem Projekt nicht angewendet.
Die Performance der KNN, Random Forest und Support Vector Machines waren weniger gut als LR und GB, daher werden nur die beiden letzteren weiter untersucht und optimiert.
Logistic Regression
Manche Ml Algorithmen, so wie Logistic Regression, haben Schwierigkeiten, einen asymmetrischer Datensatz (Imbalanced Classes) korrekt zu klassifizieren. Sie würden eine sehr hohe Accuracy im Training erreichen, um dann bei den Testdaten zu versagen. Dies liegt daran, dass sie die meisten Instanzen der überproportional repräsentierten Klasse zuordnen würde. Um dies zu verhindern, gibt es mehrere Herangehensweisen, zwei davon werden hier angewandt: Oversampling mit SMOTE und Anpassung der Hyperparameter.
Zudem wird der Datensatz skaliert.
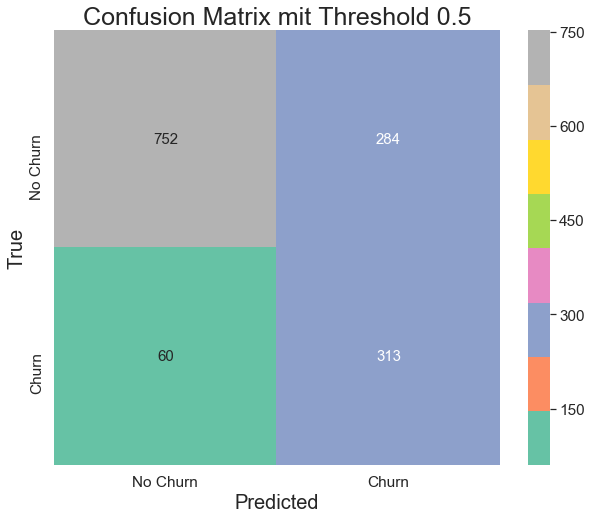
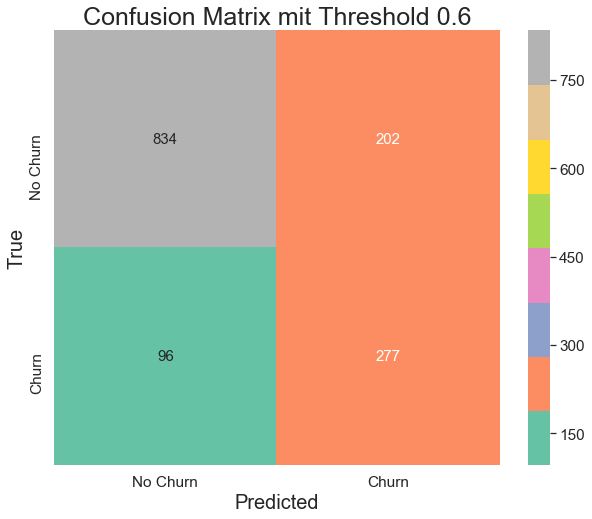
Logistic Regression mit verschiedenen Thresholds
Der voreingestelle Threshold bei Logistic Regression ist 0.5. Wird der Threshold gesenkt, erhöht sich die Sensitivity (Recall). Wird der Threshold erhöht, erhöht sich die Specificity. Das beste Model ist das mit dem Threshold von 0.6 und einem F1-Score von 0.65.
Gradient Boosting
EIst eine Machine Learning Technik für Regression und Klassifikationsprobleme, die ein Vorhersagemodell in der Form eins Ensembles erstellt. Das Ensemble besteht meist aus schwachen Vorhersagemodellen, meistens Decision Trees. Wie andere Boosting Methoden baut es das Modell in mehreren Stufen und generalisiert diese durch Optimierung durch eine Arbitrary Differentiable Loss Function. Jedes neue Modell fittet die vorher am schwierigsten zu klassifizierenden Beobachtungen. Resampling und skalieren sind bei Gradient Boosting mit Entscheidungsbäumen nicht nötig.
Hyperparameter Tuning
Folgende Parameter werden in verschiedenen Kombinationen getestet:
max_depth: Maximale Tiefe eines Baumes. Kontrolliert Overfitting
n_estimators: Anzahl an Bäumen
learning_rate: Regularisierung
Der F1-Score liegt bei 0.58, viel schlechter als Logistic Regression!
Random Forest Classifier
Random Forest zeigt die schlechteste Performance der getesteten Algorithmen mit einem F1-Score von 0.54.
Zusammenfassung
Folgede Schritte wurden im Projekt unternommen:
Bereinigung der Daten und Exploration
Feature Engineering
Vergleich und Auswahl von Algorithmen
Hyperparameter Tuning des besten Algorithmus
Testen zweier verschiedenen Feature-Sets
Das beste Model auf dem Test-Set wurde evaluiert
Bestes Model
Das beste Modell war der resampelte und skalierte Datensatz in Kombination mit Logistic Regression.
Verbesserungsmöglichkeiten
Ein anderer Ansatz. Bei den bisherigen Machine Learning Ansätzen konnte vorhergesagt werden, ob ein Kunde kündigt oder nicht. Ein Faktor blieb dabei aber außen vor: Der Zeitrahmen. Um eine Zeitskala miteinzubeziehen, kann es sinnvoll sein, Survival Analysis in Betracht zu ziehen. Survival Analysis wird normalerweise in der Epidemiologie und Pharma Forschung verwendet, um die Überlebenswahrscheinlichkeit einer Gruppe von Patienten vorherzusagen. Eines der dort verwendeten Tools ist das Cox Proportional Hazards Model.
Nicht jeder Kunde wird vermisst, wenn er geht. Daher ist es sinnvoll, den Verlust für jeden Kunden zu berechnen, falls er geht und dann entsprechend die Investitionen abzustimmen.
Sinnvoll wäre auch eine Abschätzung darüber, ob ein Kunde auf Promotions und andere Halteversuche überhaupt anspricht.
Weitere Erkenntnisse
Hier wurden sequenziell Algorithmen ausgesucht, die passen könnten, wobei nur der erste gute Ergebnisse zeigte. In künftigen Projekten sollten mehrere Algorithmen auf einmal getestet werden, um einen ersten Überblick zu erhalten, welcher der Algorithmen geeignet ist.