Was ist ein gutes Modell?
Einführung
Das Ziel beim angewandten Machine Learning ist es, das Modell zu finden, das für die gegebene Aufgabe die relevantesten Vorhersagen machen kann. Doch wie kann man garantieren, dass ein Modell zuverlässig gute Vorhersagen macht? Und gibt es noch weitere Anforderungen an ein gutes Modell?
Die Qualität eines Machine Learning Modells wird durch viele Faktoren beeinflusst. Dazu gehören in erster Linie natürlich die Auswahl des Lernalgorithmus und die Qualität des Datensatzes.
Mit der Auswahl des Lernalgorithmus wird bestimmt, wie die Ergebnisse dargestellt werden und wie groß der Hypothesen-Raum ist. Bei einer Logistischen Regression beispielsweise, ist das Ergebnis eine Funktion, bei Entscheidungsbäumen ein Satz von Regeln, die auch graphisch als Baum dargestellt werden können.
Wichtig ist es, den gewählten Lernalgorithmus vor seiner Verwendung gut zu kennen und den Datensatz entsprechend seiner Voraussetzungen und Annahmen anzupassen. Mit der Anpassung der Hyperparameter des Lernalgorithmus kann dieser für die vorliegende Aufgabe so angepasst werden, dass er optimal lernen kann. Über die Hyperparameter kann beispielsweise die Art der Regularisierung oder eine Festlegung von Verlustfunktion und Optimierungsstrategie stattfinden.
Der Datensatz soll eine gute Repräsentation der untersuchten Domäne sein. Die Anzahl von Beobachtungen und Relevanz der Attribute bestimmen, wie gut das Modell am Ende sein wird. Die Stichprobe sollte dabei die gleichen statistischen Merkmale wie die Gesamtpopulation haben, fehlerfrei und vollständig sein.
Bei der Entwicklung des Modells soll diejenige Kombination dieser drei Komponenten gefunden werden, mit der das Modell die Vergangenheit am besten interpretieren kann und damit für die Zukunft die sichersten Vorhersagen macht. Dies geschieht in einem experimentellen Prozess, bei dem verschiedene Hypothesen getestet und bewertet werden. Es gibt viele verschiedene Methoden der Evaluierung, um die Qualität der Daten, das Lernverhalten des Algorithmus und seine Generalisierungsfähigkeit im Verlauf des Projektes einzuschätzen und zu optimieren.
Es sollte stets bedacht werden, dass kein Modell jemals ein perfektes Abbild der Natur darstellen kann. Modelle sind immer lückenhaft und oberflächlich, was daran liegt, dass nie alle Variablen, die für ein Ergebnis bedeutend sind, darin aufgenommen werden können. Dennoch können auch einfache Modelle überraschend gute Approximationen der Realität darstellen und gute Vorhersagen machen. George Box sagte es schon- es geht nicht darum, ein komplett wahres Modell zu erschaffen, sondern darum, eines zu haben, das aufschlussreich und nützlich ist.

Auszug aus „Robustness in the Strategy of Scientific Model Building“ von G.E.P. Box
Die Metrik
Alle Entscheidungen, die im Laufe des Aufbaus eines Modells getroffen werden sind auf Basis des Scores einer Metrik.
Zur Auswahl eines Lernalgorithmus werden in einer Kreuzvalidierung mehrere Lernalgorithmen, die für den vorliegenden Fall in Frage kommen, getestet. Derjenige, der auf dem Datensatz am besten performt, wird zur weiteren Optimierung ausgewählt.
Um für den gewählten Algorithmus die beste Kombination der Hyperparameter zu finden, wird in einer Kreuzvalidierung angewendet, deren Score für jede mögliche Kombination eingeschätzt wird. Verschiedene Kombinationen von Feature Sets werden nacheinander getestet und bewertet. Auch die Einschätzung des Lernverhaltens des Algorithmus im Training und Test und zu guter Letzt die Generalisierungsfähigkeit des Modells auf dem Test Set setzen die Verwendung einer Metrik voraus.
Es gibt sehr viele Metriken, die zur Auswahl stehen und jede hat einen unterschiedlichen Schwerpunkt bei der Einschätzung von Fehlern. Beispielsweise ist der Unterschied zwischen den Regressionsmetriken RMSE und MAE, dass MAE robust ist, wenn sich Ausreißer im Datensatz befinden.
Eine gute Metrik zeichnet sich dadurch aus, dass sie leicht anzuwenden, interpretieren und kommunizieren ist. Daher ist es sehr wichtig, die richtige Metrik zu wählen, die zur Aufgabe passt und das Richtige misst.
Da verschiedene Metriken nicht direkt miteinander verglichen werden können, hat es sich in der Praxis bewährt, eine Metrik auszuwählen und während aller Schritte des Projekts dabei zu bleiben. Hierfür kann in Scikit-Learn ein Scorer definiert werden.
Alles ist relativ
Nehmen wir an, dass unser Modell einen Accuracy Score von 80% erreicht auf dem Test Set erreicht hat. Was bedeutet dies nun für das Modell? Ist das Ergebnis gut oder eher nicht?
Der mit einer Metrik ermittelte Performance Score eines Modells hat für sich alleine genommen keine Aussagekraft. Er ist eine relative Angabe und um zu wissen, ob das Modell, das man entwickelt hat, ein gutes Modell ist, muss es mit anderen Möglichkeiten, diese Ergebnisse zu gelangen, verglichen werden können. Eine der anderen Möglichkeiten wird dafür als Baseline verwendet. Wenn das Modell mindestens so gut ist, wie andere Herangehensweisen, oder sie im besten Fall übertrifft, hat man ein gutes Modell geschaffen.
Für die einfachste Form einer Baseline können statistische Parameter verwendet werden. Hierfür werden beispielsweise bei einer Klassifikation die Vorhersage der häufigsten Klasse oder bei einer Regression der Mittelwert der Ergebnisse angenommen und deren Score berechnet. Eine Metrik, die einen direkten Vergleich zwischen Baseline und Modell verwendet, ist Cohens Kappa, der einen Accuracy Score ausgibt, welcher mit der Baseline normalisiert wurde. Die Baseline Accuracy ist 0 und alle Scores darüber bedeuten eine Verbesserung. In Scikit-Learn gibt es die Möglichkeit, mit einem Dummy-Modell Baselines zu erzeugen.
Eine weitere Möglichkeit des Vergleichs sind andere Modelle, die für diese oder eine ähnliche Aufgabe in der Vergangenheit verwendet wurden oder gegenwärtig verwendet werden (State of the Art).
Soll ein Problem zum ersten Mal mit der Hilfe Machine Learning gelöst werden, kann die Performance von Experten der Domäne mit traditionellen Methoden als Vergleich herangezogen werden.
Schafft man es nicht, die Baseline zu erreichen, kann dies verschiedene Ursachen haben. Es kann daran liegen, dass der Lernalgorithmus für die Aufgabe unpassend gewählt ist oder der Datensatz die Domäne nicht ausreichend repräsentiert.
Auch eine nicht ausreichende Spezifikation der Aufgabe kann hier die Ursache sein. Natürlich kann die Art der Aufgabe auch einfach nicht für eine Verwendung von Machine Learning Methoden geeignet sein.
Die Methode
Die Holdout-Methode
Der gelabelte Datensatz wird in zwei sich gegenseitig ausschließende Mengen aufgeteilt, in eine größere Trainingsmenge und eine kleinere Testmenge. In der Praxis wird meistens ein Split von 80/20 verwendet.
Der Vorteil dieser Methode ist, dass die Trainingszeit relativ kurz ist. Es sollte beachtet werden, dass, je nach Split, die Qualität des Modells variieren kann und vor allem bei kleinen Trainingssätzen die Varianz sehr hoch sein kann. In Scikit-Learn wird für diese Form der Aufteilung Train_Test_Split verwendet.
Three-Way-Holdout
Sind genug Daten vorhanden, kann eine Variante der Holdout Methode angewendet werden, bei der der Datensatz in drei Sets aufgeteilt wird, nämlich ein Trainings Set, Test Set und Development Set. Dieses wird für das Auffinden der besten Hyperparameter-Kombinationen verwendet. Mit dieser Aufteilung soll Data Leakage vermieden werden, da die Hyperparameter auf einem gesonderten Satz angepasst werden. In Scikit-Learn wendet man Train_Test_Split hierfür einfach zweimal an.
K-Fold Cross Validation
Die anspruchsvollere Alternative zu den Holdout Methoden sind Resampling Methoden wie K-Fold Cross Validation und Bootstrapping. Diese sollten immer dann angewendet werden, wenn die Datenmenge begrenzt ist. Hierfür wird das Trainingsset in k Subsets (‚Folds‘) aufgeteilt und das Model k-mal trainiert und evaluiert. In jeder Iteration werden k-1 Folds für das Training und 1 Fold für die Evaluierung verwendet. Das Ergebnis ist ein Array mit k Evaluierungs-Scores, aus denen der Mittelwert für den Gesamt-Score berechnet wird.
Bei der Anwendung des Modells sollte das stochastische Element nicht außer Acht gelassen werden. Viele Machine Learning Algorithmen verwenden Zufallszahlen, wie zum Beispiel bei der Initialisierung von Koeffizienten bei Neuronalen Netzen. Dies schlägt sich auch in der Performance nieder, daher im Zweifelsfall Kreuzvalidierung verwenden. Hier sollte die Varianz des Scores gering und der Erwartungswert konstant sein, um ein robustes Modell zu garantieren.
Die Kreuzvalidierung mit k = 10 hat sich in Experimenten als am genauesten gezeigt. Es ist sinnvoll, immer eine stratifizierte Zufallsstichprobe (‚Stratified Sampling‘) verwenden (Wird bei Scikit-Learn automatisch verwendet).
Der Vorteil dieser Methode ist, dass sie sehr gute Ergebnisse liefert, allerdings ist sie dabei sehr rechenintensiv. In Scikit-Learn werden sie automatisch beim Hyperparameter Tuning mit Grid Search oder Randomized Search verwendet. Wenn ein Modell zu viele Fehler bereits im Training macht, kann versucht werden, statt der Holdout-Methode eine Kreuzvalidierung zu verwenden.
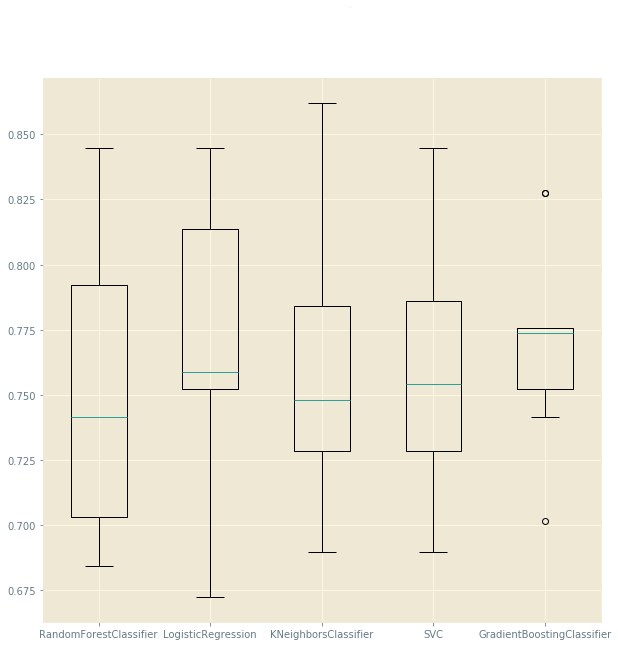
Ergebnis einer Kreuzvalidierung für die Auswahl eines Algorithmus aus dem Projekt Eine Erkrankung an Diabetes vorhersagen.
Finde die Fehler
Bei der Fehleranalyse werden vom Modell gemachte Fehler genauer unter die Lupe genommen, um Fehlerquellen zu finden und zu eliminieren.
Die drei Hauptquellen für Fehler im Modell sind Bias, Varianz und Rauschen. Es gibt verschiedene Methoden, diese Fehler zu finden und das Modell zu verbessern. Fehler, die aus der Anpassung des Lernalgorithmus an die Daten kommen, können mit der Hilfe von Lernkurven und Validierungskurven ermittelt werden.
Fehler im Datensatz können oft vermieden werden, indem dem Modellieren eine gute Exploration und Bereinigung der Daten vorausgeht.
Es ist auch wichtig, den oder die Lernalgorithmen, die man verwendet möchte, gut zu kennen, um zu wissen, welche Anforderungen sie an die Daten stellen und an welchen Stellen es durch ihre Funktionsweise Probleme geben könnte.
Die Analyse von Fehlern ist ein empirischer Vorgang, bei dem Domainwissen und Kreativität gefragt sind. Die beste Vorgehensweise ist es, für jeden Fehler, den das Modell macht, für die möglichen Ursachen aufzustellen und anschließend mögliche Ansätze zur Reduzierung des Fehlers zu testen.
Die richtige Basis
Der Datensatz soll den Ausschnitt der Realität, der modelliert werden soll, so gut wie möglich repräsentieren, den er ist die Grundlage des Modells (Garbage in, garbage out). Die Prämisse ist, dass diese durch eine unbekannte Zielfunktion erzeugt wurden, die durch den Lernalgorithmus mit Hilfe der Daten approximiert wird. Diese Art des Lernens wird als Induktives Lernen bezeichnet.
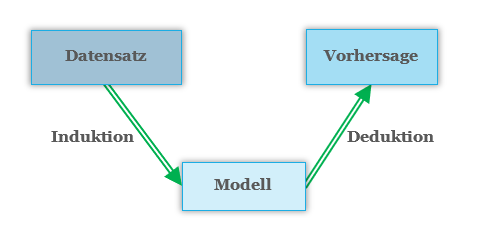
Induktion und Deduktion im Machine Learning
Dies bedeutet, dass jede kleine Veränderung in der Bearbeitung des Datensatzes im Lauf des Projekts, von der Zusammenstellung der Primärdaten, über die Exploration und Bereinigung, dem Feature Engineering und Preprocessing bis hin zum Aufteilen des Datensatzes für das Training und Testen in einem etwas anderen Modell mit anderen Ergebnissen resultiert.
Ganz gleich, wie viele Attribute dem Datensatz hinzugefügt werden, er wird nie vollständig sein und die komplette Realität darstellen. Wäre dies möglich, so müsste kein Machine Learning verwendet werden, sondern alle bekannten Größen könnten in eine Formel integriert werden und man würde für gleiche Eingaben immer das gleiche Ergebnis erhalten.
So lange es also nicht möglich ist, alle Attribute, die einen Prozess zu beschreiben, in den Datensatz aufzunehmen, wird jeder Datensatz etwas verrauscht sein. Dieses Rauschen kann reduziert, aber nie ganz eliminiert werden. Die Variablen, die unabhängige und abhängige Variablen beeinflussen können, aber nicht im Datensatz sind, werden als Drittvariablen (Confounder) bezeichnet.
Um herauszufinden, ob dem Datensatz wesentliche Informationen fehlen, kann bei einer Regressionsanalyse die Verteilung der Residuen untersucht werden. Sind diese nicht normalverteilt, liegt dies möglicherweise an fehlenden Variablen. Bei einer Klassifizierung sollte die Verteilung der Ergebnisse ähnlich sein, wie in der Stichprobe. Ist dies nicht der Fall, so kann es an fehlenden Informationen oder unausgeglichenen Klassen liegen, also zu wenige Instanzen einer Klasse im Trainingsdatensatz vorhanden sein. Ein anderer Hinweis für zu viele fehlende Informationen ist eine zu hohe Varianz der Trainings-Scores in der Kreuzvalidierung.
Da ein Datensatz immer eine Zufallsstichprobe ist, also eine Sammlung von zufälligen Beobachtungen die aus der untersuchten Domäne ausgewählt wurden, sollte immer darauf geachtet werden, dass er die gleichen statistischen Parameter wie die Grundpopulation aufweist und tatsächlich zufällig ist und keine Verzerrungen aufweist. Eine gute Datengrundlage ist fehlerfrei, repräsentiert die zugrundeliegende Realität so vollständig und eindeutig wie möglich und ist an die Ansprüche des Lernalgorithmus angepasst, um zu gewährleisten, dass dieser gut lernen kann.
Bei linearen Lernalgorithmen kann es helfen, Informationen im Datensatz durch das Hinzufügen von Interaktionstermen und Polynomialen Termen klarer herauszustellen, damit diese Muster leichter erkannt und abgebildet werden können.
Bei einer Klassifikation kann es das Modell verbessern, den Datensatz auszugleichen, so dass von jeder Klasse ungefähr gleich viele Beobachtungen vorhanden sind. Mehr dazu im Artikel Klassifizierung.
Der passende Lernalgorithmus
Der Algorithmus soll die richtigen Muster finden und abbilden. Für die Darstellung gibt es viele Auswahlmöglichkeiten, so können die gefundenen Regeln beispielsweise als Funktion oder als Entscheidungsbaum dargestellt werden. Über die Hyperparameter wird der Lernalgorithmus an die vorliegende Aufgabe angepasst, um das Lernen zu optimieren, sie bestimmen beispielsweise, wie stark dieser reguliert wird, oder welche Verlustfunktion verwendet wird.
Das Ziel des Lernens ist eine gute Anpassung des Lernalgorithmus an die gegebenen Daten und eine gute Abstraktion, um später für unbekannte Daten gute Vorhersagen machen zu können.
Im Idealfall findet der Algorithmus die Mitte zwischen zwei Extremen, der Überanpassung und der Unteranpassung (Bias-Varianz Dilemma).
Unteranpassung (Underfitting) zeigt sich, wenn das Model nur oberflächlich aus den Trainingsdaten lernt. Dies resultiert in einem hohen Bias. Das Bias ist der durchschnittliche Fehler, den ein Lernalgorithmus auf verschiedenen Trainingssätzen macht. Das Modell ist beim Lernen nicht genug in die Tiefe gegangen und hat keine Muster gelernt, die die Beispiele umreißen und auf neue, unbekannte Beispiele angewendet werden können. Die Unteranpassung zeigt sich darin, dass die Performance bereits im Training eine schlechte Performance hat.
Überanpassung (Overfitting) geschieht, wenn das Model jedes Detail der Trainingsdaten perfekt lernt. Dies resultiert in einer hohen Varianz, also Sensitivität des Modells für die Daten. Zufällige Fluktuationen und Rauschen werden vom Model als Muster erkannt und gelernt, was wiederrum bedeutet, dass das Model schlecht generalisieren wird und die Performance auf neuen, unbekannten Daten schlechter ist. Wenn das Model overfitted, lernt es quasi die Trainingsbeispiele auswendig, und kann neue Instanzen nur richtig einordnen, wenn sie genau wie die Trainingsbeispiele beschaffen sind. Overfitting kann daran erkannt werden, dass das Modell sehr gute Ergebnisse auf dem Trainingssatz hat und sehr schlechte Ergebnisse im Test.
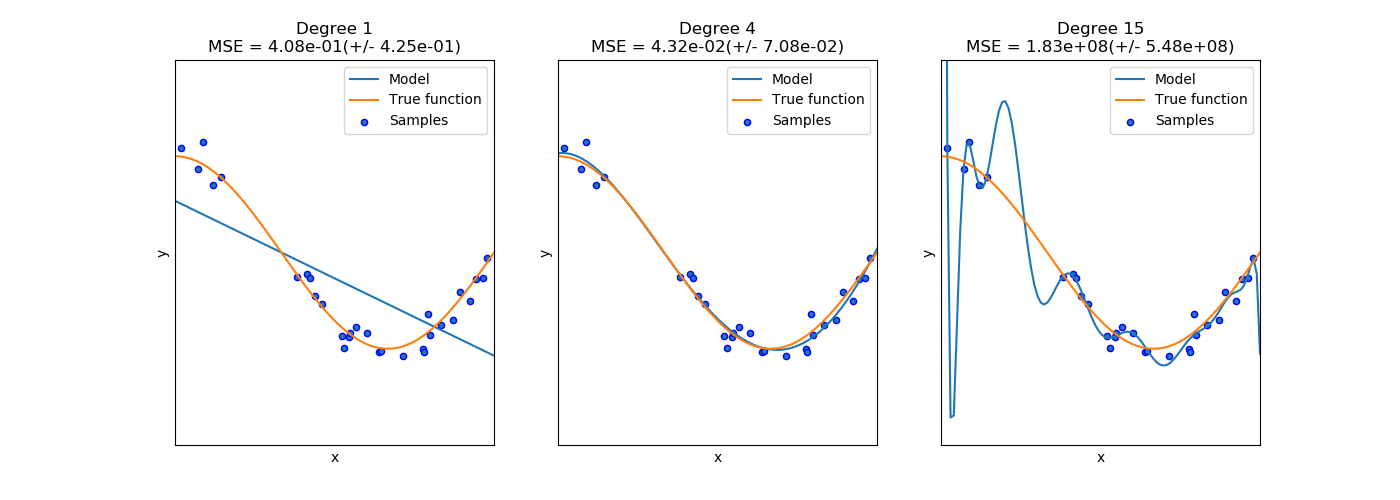
Overfitting und Underfitting: Von links nach rechts eine Darstellung von Underfitting, Idealem Fit und Overfitting
Modelle mit einer hohen Varianz oder einem hohen Bias können eine ähnliche Fehlerrate aufweisen, daher lohnt es sich, genauer hinzusehen, um zu determinieren, welcher Art der Fehler ist.
Eine Möglichkeit ist eine grafische Methode, bei der Lern- und Validierungskurven analysiert werden. Dafür werden die Performance auf den Trainingsdaten und den Testdaten geplottet, um die Performance eines Modells über die Zeit, bzw. Erfahrung (Anzahl der verarbeiteten Beobachtungen), während es von den Trainingsdaten lernt, darzustellen.
Eine weitere Methode ist die Bias-Variance-Decomposition. Sie kann bei Regressionsaufgaben und zusammen mit probabilistischen Klassifikatoren angewandt werden.
Die besten Hyperparameter
Die Scores von Test und Training in Abhängigkeit eines Hyperparameters können in einer Validierungskurve visualisiert werden. Unten das Beispiel einer Validierungskurve eines Support Vector Classifier-Models mit dem Performance Score in Abhängigkeit von verschiedenen Werten für den Hyperparameter γ (Bestimmt Verwendung des Kernels). Der Klassifikator funktioniert am besten mit den mittleren Werten für γ, wo der Score in Training und Test gleich gut sind. Für Werte darüber stellt sich Overfitting ein, im Trainings-Set ist die Performance hervorragend, fällt aber bei der Validierung rapide ab.
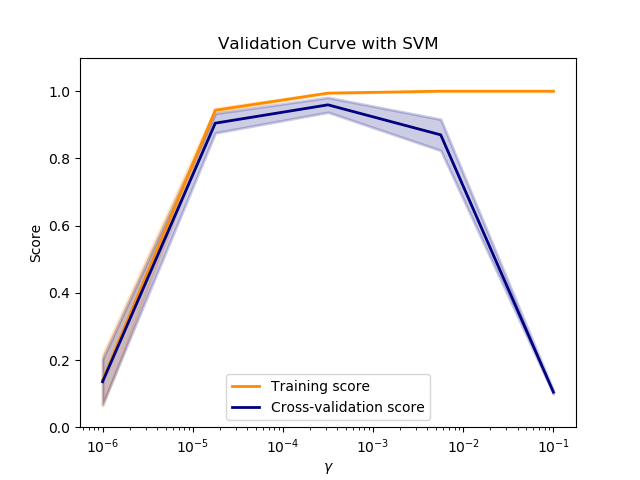
Beispiel aus Scikit-Learn von hier.
Ist ein gutes Modell ein komplexes Modell?
Die Stellschraube für die Regulierung von Fehlern ist die Komplexität des Modells. Bias und Varianz werden über den Lernalgorithmus und seine Hyperparameter-Einstellungen manipuliert, das Rauschen in den Daten kann durch die Anzahl der Attribute beeinflusst werden. Der Bias ist hoch, wenn die reale Beziehung komplex ist und das Modell zu einfach, um diese abzubilden. Die Varianz ist hoch, wenn verschiedene Stichproben in großen Änderungen resultieren. Einfache Modelle werden eher zu wenig angepasst sein, komplexe Lernalgorithmen tendieren eher zur Überanpassung, da sie flexibler beim Aufstellen der Zielfunktion sind und auch das Rauschen als Signal abbilden. Allgemein kann also gesagt werden, je komplexer das Modell, desto größer der Hypothesenraum und desto höher die Tendenz zum Overfitten.
Kriterien der Komplexität
- Mehr Features erhöhen die Komplexität des Modells. Damit wird die Varianz erhöht und das Bias gesenkt. Das Hinzufügen von Features kann durch neue Variablen im Datensatz oder durch Hinzufügen von Polynomialen oder Interaktions-Termen geschehen. Weniger Features dagegen senken die Varianz und erhöhen den Bias.
- Die Anzahl der Beobachtungen haben keinen Einfluss auf den Bias, aber mit mehr Beobachtungen kann die Varianz verringert werden.
- Je komplexer der Lernalgorithmus, desto höher die Varianz und desto geringer das Bias.
- Je höher die Regularisierung des Lernalgorithmus, desto geringer die Varianz und desto höher das Bias.
Stellt sich heraus, dass das Modell überangepasst ist, kann es helfen, ein Development Set oder eine Kreuzvalidierung für die Anpassung der Hyperparameter zu verwenden.
Oft ist ein einfaches Modell, also ein Modell, das dem Prinzip der Parsimonie entspricht, einem komplexen Modell vorzuziehen. Ein solches Modell bringt die Vorteile mit sich, dass es einfach zu interpretieren ist, schnell im Training und im Einsatz ist und weniger Speicherplatz benötigt. Bei der Entwicklung eines Machine Learning Modells ist sinnvoll, mit einem einfachen Modell zu beginnen und die Komplexität nur soweit zu steigern, wie nötig. Den Zusammenhang von vorhandenen Variablen und Anzahl der Beobachtungen sollte dabei nicht außer Acht gelassen werden (Curse of dimensionality).
Die Quantifizierung von Vertrauen
Im Machine Learning wird, wie in der Statistik, immer mit unvollständiger und imperfekter Information gearbeitet. Es ist prinzipiell unbekannt, welche Variablen und welcher Lernalgorithmus am besten geeignet sind, um ein Problem zu repräsentieren.
Es wird immer Fälle geben, die unbeobachtet bleiben und ganz gleich, wie gut das Modell generalisieren kann, so kann dies nur aufgrund der tatsächlich beobachteten Fälle.
Durch Experimentieren werden Hypothesen getestet und verworfen, bis eine gefunden ist, die das Problem gut genug umreißen kann und Ergebnisse produziert, die von Nutzen sind. Dies bedeutet, dass es immer eine gewisse Unsicherheit bei den Ergebnissen gibt.
Daher gibt es neben der Metrik, die eine Aussage darüber macht, wie gut eine Hypothese die Zielfunktion approximiert, und wie gut sie im Vergleich zu anderen Modellen und Herangehensweisen ist, noch einen anderen Wert, der immer angegeben werden sollte und das ist die Aussage über das Vertrauen in die Richtigkeit der Ergebnisse. Hierfür können Methoden aus dem Bereich der New Statistics verwendet werden, um Aussagen über einzelne Vorhersagen und das komplette Modell zu quantifizieren und das Vertrauen in ein Modell zu bemessen.
Vertrauen in die Vorhersage
In der Regressionsanalyse wird das Vorhersageintervall (Prediction Interval) verwendet, um zu zeigen, wie sicher die Vorhersage ist. Dabei werden der Punkt und ein Bereich um diesen herum angegeben.
Bei einer Klassifizierung kann dies mit der Verwendung der kalibrierten Wahrscheinlichkeiten geschehen. Bei der Verwendung von Logistic Regression können die Wahrscheinlichkeit, dass die Beobachtung zu einer Klasse gehört, direkt als Konfidenz in die Vorhersage interpretiert werden. Bei anderen Klassifikatoren müssen die Wahrscheinlichkeitsangaben zuvor kalibriert werden.
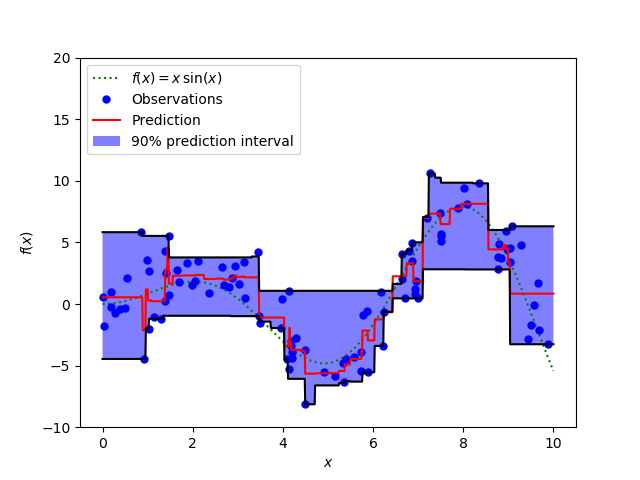
Vorhersageintervall einer Regressionsanalyse aus Scikit-Learn.
Vertrauen in das Modell
Ein Konfidenzintervall gibt die Wahrscheinlichkeit (Konfidenzniveau) an, mit der es einen statistischen Parameter, wie den Mittelwert, beinhalten wird. Ein Konfidenzniveau von 95% bedeutet, dass 95% aller Konfidenzintervalle den tatsächlichen Wert beinhalten werden.
Im Machine Learning können Konfidenzintervalle verwendet werden, um die Unsicherheit einer Abschätzung zu quantifizieren. Je kleiner ein Konfidenzintervall, desto präziser die Schätzung.
Praktisch kann dies mit der Verwendung von Bootstrapping geschehen, um für verschiedene Performance Metriken des Modells, wie Accuracy, Recall oder Precision Konfidenzintervalle anzugeben.
Auch die Verteilung der Koeffizienten eines Modells kann mit Bootstrapping abgeschätzt werden und dann beispielsweise in einem Boxplot visualisiert werden.
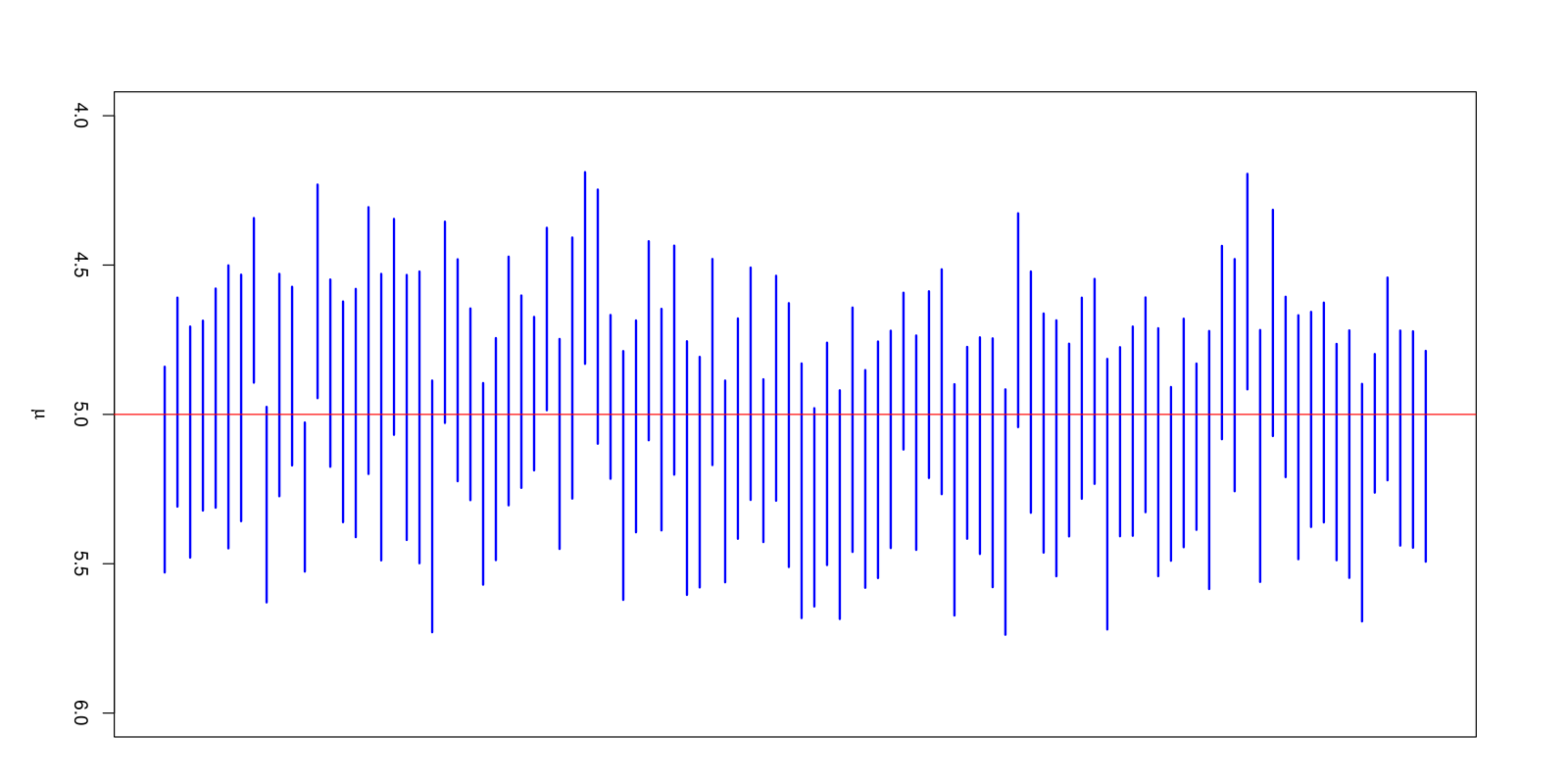
Konfidenzintervalle zum Niveau 95 % für 100 Stichproben vom Umfang 30 aus einer normalverteilten Grundgesamtheit. Davon überdecken 94 Intervalle den exakten Erwartungswert μ = 5; die übrigen 6 tun das nicht. Aus Wikipedia.
Die Erklärung des Modells
Bei vielen Anwendungen ist es notwendig und bei allen Anwendungen ist es sicherer, das Modell zu interpretieren, um verstehen zu können, wie der Computer zu seinen Ergebnissen und Entscheidungen kam.

Ein Mem aus „Little Britain„
Bei der Modellinterpretation wird mit verschiedenen Methoden offengelegt, wie die Features vom Modell in ihrer Wichtigkeit eingeschätzt werden, welche also den größten Einfluss auf eine Vorhersage haben.
Nicht jedes Machine Learning Modell muss interpretiert werden. Es kommt hier vielmehr darauf an, wie das Modell eingesetzt wird. Werden Menschen direkt von den Entscheidungen des Modells beeinflusst? Dann sollte das Modell immer erklärbar sein. Es kann sich jedoch lohnen, auch bei Modellen, bei denen dies nicht der Fall ist, genauer hinzusehen, um zu verstehen, welche Prozesse im Inneren ablaufen und nachvollziehen zu können, wie und auf welcher Basis Entscheidungen getroffen werden.
Leider sind die meisten Machine Learning Modelle sehr komplex und daher kaum ohne weiteres durch den Menschen zu verstehen. Für die Interpretation und Erklärung dieser gibt es mehrere Möglichkeiten, ihre Arbeitsweise offenzulegen.
Das Wissen aus einer Interpretation hilft, Einsichten in die Natur des Problems zu gewinnen und es aus verschiedenen Blickwinkeln zu beleuchten. Fehler der inneren Logik des Systems können aufgedeckt und reduziert werden.
Auch aus Gründen der Fairness und Ethik ist die Interpretation sollten Modelle erklärt werden, um Einsichten in mögliche systematische Fehler wie Vorurteile gegen bestimmte Gruppen zu bekommen. Diese aufzudecken ist von großer Bedeutung, denn sie werden vom Modell nicht nur aufgenommen, sondern im schlimmsten Fall auch verstärkt.
Ein berühmtes Beispiel, das für die Interpretation von Modellen spricht, stammt aus einem Vortrag für den LIME Algorithmus. Die Forscher hatten ein Modell entwickelt, das Fotos von Huskies und Wölfen klassifizieren sollte. Der Accuracy-Score des Modells war sehr gut, die Wölfe wurden zuverlässig von den Huskies unterschieden. Bei der Interpretation fand sich jedoch, dass sich das Modell nicht auf die Tiere, sondern den Hintergrund der Bilder konzentriert hatte. Zufälligerweise war auf jenen Bildern, die Wölfe zeigten, die Landschaft immer verschneit. So hatten die Entwickler einen Schneedetektor gebaut, der keine Ahnung von Hunden und Wölfen hatte. Eine nicht repräsentative Stichprobe hat in diesem Fall zu Verwirrungen beim Klassifikator geführt.
Bei der Interpretation eines Modells, das verwendet wurde, um das Risiko von Lungenentzündungspatienten einzuschätzen, fand sich, dass das Modell Patienten, die zudem an Asthma litten, als risikoärmer eingestuft worden waren, als zuvor gesunde Patienten. Dies widerspricht jedoch allem, was ein Experte aus der Domäne sagen würde. Der Grund dieser Einstufung war, dass Asthmapatienten eher dazu neigen, sich untersuchen zu lassen, wenn sie spüren, dass ihre Atmung verändert ist. Damit wurde die neue Erkrankung bei diesen oft früher entdeckt und sie wurden dementsprechend früher behandelt. Der Grund für das geringere Risiko war also nicht das Asthma, sondern die Aufmerksamkeit des Patienten.
COMPAS ist ein Modell, das in den USA dazu verwendet wird, die Rückfallwahrscheinlichkeit eines aus der Strafvollzugsanstalt entlassenen Menschen, abzuschätzen,
Dieses hat das unglückliche Bias, Menschen, die nicht weiß waren, eine größere Rückfallwahrscheinlichkeit zuzusprechen, als anderen. Möglicherweise war das Modell in sich korrekt, es hatte entsprechende Muster in den Trainingsdaten gefunden und verwendet. Die Ergebnisse sind jedoch ethisch nicht vertretbar.
Manche Modelle können Wichtigkeit der Variablen direkt ausgeben. Dazu gehören Modelle, die auf Entscheidungsbäumen basieren, wie Random Forest oder Boosted Trees und auch parametrische Modelle, wie die Lineare Regression. Um zuverlässige Ergebnisse zu erhalten, müssen die Ansprüche der Lernalgorithmen dafür unbedingt eingehalten werden. Liegt beispielsweise in einem Datensatz für eine Regressionsanalyse Multikollinearität vor, so können die Koeffizienten nicht mehr zuverlässig interpretiert werden.
Ist ein Modell zu komplex für eine direkte Interpretation, so gibt es verschiedene Methoden, die angewendet werden können, um den Deckel der Black Box zu lüften. Beispiele hierfür sind die Verwendung globaler Surrogat-Modelle, die Permutation Feature Importance, Partial Dependence Plots oder Local Interpretable Model-Agnostic Explanations (LIME) bzw. Shapley Additive Explanations (SHAP).
Näheres zu diesen findet sich im Artikel Die Interpretation von Machine Learning Modellen.
Rekapitulation und Ausblick
Was bedeutet es nun also, ein gutes Modell zu haben? Einige Einflüsse auf die Modellqualität wurden in diesem Artikel besprochen. Damit könnte die Frage folgendermaßen beantwortet werden:
Ein Modell, das gute Vorhersagen macht. In diesem Artikel wurden Ansätze und Methoden besprochen, wie die Qualität der Vorhersagen eines Modells eingeschätzt und verbessert werden können. Doch ein gutes Modell ist viel mehr, als eines, das korrekte Vorhersagen produziert.
Ein einfaches Modell. Mit steigender Komplexität können sich die Vorhersagen verbessern, aber oft ist ein einfaches Modell dennoch die bessere Wahl. Am besten, man hält das Modell so einfach wie möglich und macht es nur so komplex, wie nötig.
Ein vertrauenswürdiges Modell. Anhand von Vorhersage- und Konfidenzintervallen wurde gezeigt, dass den Ergebnissen aus dem Modell vertraut werden kann.
Ein Modell, das in sich logisch ist und dem Wissen und den Erfahrungen aus der Domain entspricht. Mit der Interpretation können die inneren Abläufe im Modell beleuchtet werden und daraufhin untersucht werden, ob sie in sich logisch sind.
Ein Modell, das fair ist und keine menschlichen Vorurteile weiterführt und verstärkt. In einer Welt, in der wir als Individuen und Gesellschaften immer mehr von Modellen beeinflusst werden, sollten ethische Fragen nie außer Acht gelassen werden.
Hier sind einige weitere wichtige Punkte, die beizeiten dem Artikel hinzugefügt werden:
Ein Modell, das formal klar definiert wurde und keine Technischen Schulden verursacht. Beim Aufbau des Modells wird darauf geachtet, dass jederzeit nachvollzogen werden kann, wie es entwickelt wurde. Es ist modular aufgebaut, der Code ist kommentiert und die Pipelines klar definiert.
Ein Modell, das im Einsatz auch über Zeit verlässlich ist. Nach dem Einsatz in der Produktion sollte es permanent überwacht werden, da es in seiner Leistung degradieren kann. Die Architektur sollte so gestaltet sein, dass es jederzeit an neue Bedingungen angepasst werden kann und Bugs schnell behoben bzw. Änderungen problemlos implementiert werden können.
Ein robustes Modell, das auch mit gezielten Angriffen (Adversarial Attacks) nicht verwirrt werden kann. Mehr dazu beispielsweise hier.
… Ein Modell, dass zwischen Kausalität und Korrelation unterscheiden kann?
