Die Entwicklung eines Machine Learning Modells
Einleitung
Beim angewandten Machine Learning ist es das Ziel, mit der Hilfe von Daten induktiv die unbekannte Zielfunktion, die diese produziert hat, mit Hilfe eines Lernalgorithmus zu approximieren. Dafür wird der Hypothesenraum für mögliche Antwortfunktionen so lange verkleinert, bis eine optimale Hypothese gefunden ist. Für die Erfüllung dieser Aufgabe gibt es eine unendliche Anzahl von möglichen Herangehensweisen und Methoden, jede mit ihren eigenen Anforderungen, Vorteilen und Hürden.
Jede Entscheidung im Verlauf der Entwicklung des Modells vereinfacht das Problem und verkleinert die Anzahl möglicher Hypothesen. Jede dieser Entscheidungen bedeutet jedoch auch das Risiko, eine Einschränkung gewählt zu haben, die das System davon abhält, aus den Daten zu lernen und die Zielfunktion zu approximieren. Die Auswahl geschieht oft im Experiment, indem mehrere Alternativen getestet und diejenige, die die beste Performance des Modells bedeutet, gewählt wird.
Diese Herangehensweise macht es besonders wichtig, sauber zu arbeiten und alle Schritte sorgfältig zu dokumentieren, um später nachvollziehen zu können, wie es zu einer Entscheidung kam und warum andere Möglichkeiten an einem Punkt ausgeschlossen worden waren. Am besten, man fängt damit an, alle möglichen Optionen an allen Entscheidungspunkten aufzulisten und empirisch zu testen, um herauszufinden, welche Kombination von Methoden die beste für die vorliegende Aufgabenstellung ist.
Der Code sollte modular aufgebaut, kommentiert und so weit wie möglich automatisiert werden, um alle Ergebnisse später reproduzieren zu können. Für häufig wiederholte Aufgaben lohnt es sich, Funktionen schreiben, die immer wieder eingesetzt werden können.
Die Verwendung von Pipelines ist eine weitere große Hilfe für die Übersichtlichkeit beim Aufbau und zur Vermeidung von Technischen Schulden.
Wie zuvor schon erwähnt, ist Machine Learning ist ein experimenteller Prozess. Daher ist es fundamental, bereits früh im Projekt erste Ergebnisse zu produzieren und dann das Modell schrittweise zu optimieren. Eine gute Herangehensweise ist es, mit einem sehr einfachen und gut zu interpretierenden Prototyp zu beginnen, um ein besseres Verständnis der Aufgabenstellung und der vorhandenen Informationen zu gewinnen und dann, wenn nötig, die Komplexität in Datensatz und/ oder Lernalgorithmus zu erhöhen. Die Ergebnisse jedes Schrittes können Hinweise auf Verbesserungsmöglichkeiten oder Änderungen in früheren Schritten und weiteres Vorgehen geben. Diese Herangehensweise ist äußerst robust und wird im angewandten Machine Learning am häufigsten praktiziert. Sind genug Daten vorhanden, kann mit der Analyse einer repräsentativen Stichprobe begonnen werden, um schnell erste Ergebnisse zu erhalten, und den kompletten Datensatz später für das Training und Testen zu verwenden.
Den besten Input für die Lösung des vorliegenden Problems können die Domain-Experten geben. Ihre Hilfe sollte bei der Zusammenstellung des Datensatzes, der Behandlung von Fehlern wie fehlender Werte oder Ausreißern und der Interpretation des Modells immer in Anspruch genommen werden.
Im Folgenden einige Punkte, die sich bei der Entwicklung eines Machine Learning Modells als nützlich erweisen könnten, um ein leistungsfähiges und robustes Modell zu erhalten.
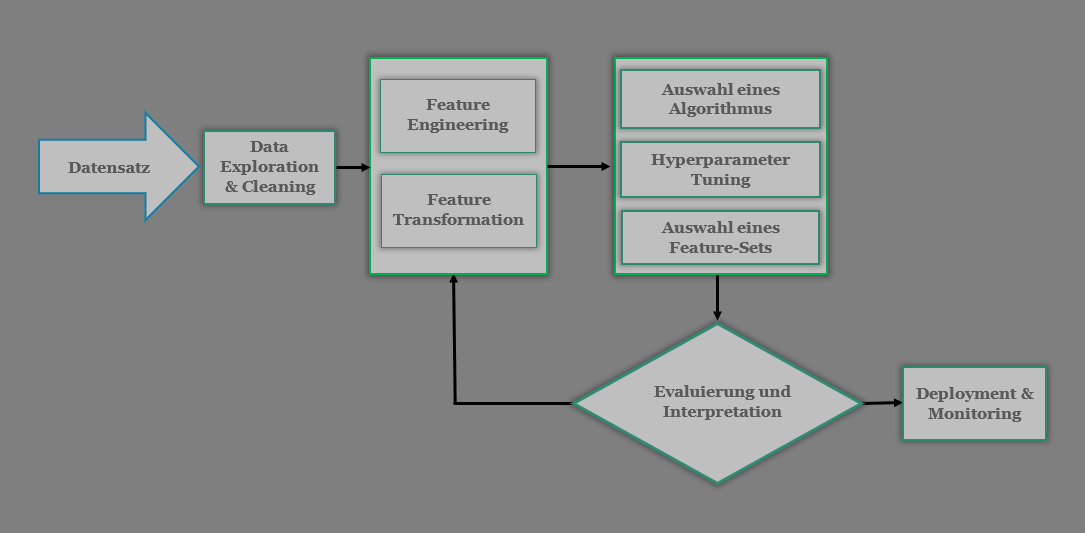
Der Ablauf eines Machine Learning Projektes
Projektdefinition und Abgrenzung
Jedes Projekt wird mit einer detaillierten Beschreibung der Problemstellung und der gewünschten Ergebnisse begonnen. Hierzu gehört auch die Definition einer Baseline und die Festlegung einer Metrik, die für das vorliegende Problem geeignet ist. Um verschiedene Lernalgorithmen, die im Modell getestet werden, einfach miteinander und der Baseline vergleichen zu können, ist es sinnvoll, sich dabei auf eine einzige Metrik zu konzentrieren, die durchgehend bei allen Schritten verwendet wird.
Problemdefinition und Motivation
- Beschreibung und Interpretation des Problems
- Motivation für die Lösung
- Wie soll das Problem gelöst werden, wie werden die Ergebnisse verwendet?
- Welche Informationen sind relevant?
- Welche Daten (Inputs und Outputs) stehen zur Verfügung, welche können dabei helfen, die Fragen zu beantworten?
- Was sind die minimalen Anforderungen, welche wären „nett zu haben“?
- Was könnte mit dem gegebenen Input noch vorhergesagt werden?
Recherche und Festlegen einer Baseline
- Recherchieren von ähnlichen Problemstellungen und deren Lösungen
- Wie wurde dieses Problem oder ähnliche Probleme in der Vergangenheit ohne Machine Learning gelöst?
- Welche Theorien gibt es zu Lösungen und zu Randbedingungen? Können diese verifiziert werden?
- Welche Baseline soll verwendet werden, um die Modellperformance einzuschätzen?
Modelldefinition
- In welcher Form ist die Zielvariable und welchem Machine Learning Typ entspricht die Aufgabe (Klassifizierung, Regression, Clustering)?
- Was sollte das Modell erfüllen?
- korrekte Vorhersagen
- gute Repräsentation der Domäne
- Ethik, Fairness, Einhalten von Rechtsvorschriften
- Was sollte das System erfüllen?
- Geschwindigkeit in Training oder im Einsatz
- Skalierbarkeit
- Robustheit gegen Angriffe oder Manipulationsversuche der Metrik
- Flexibilität
- Sicher (merkt Degeneration der Daten, merkt es, wenn sich Fehler einschleichen)
- Sollen die Vorhersagen als Batch-Vorhersagen oder als On-Demand Vorhersagen ausgegeben werden?
- Wie kann das Projekt aufgebaut werden, damit die Parameter der Problembeschreibung leicht geändert werden können?
Auswahl einer Metrik
- Welche Metrik soll verwendet werden?
- Was soll die Metrik aussagen und wofür steht sie?
- Wenn die Metrik verbessert wird, wie wirkt sich das auf das System aus?
- Kann sie manipuliert werden?
- Kann es passieren, dass sie gut ist, obwohl das System schlecht ist?
Infrastruktur
- Welche Ressourcen werden benötigt?
- Welche Software und Libraries sollen verwendet werden?
- Soll Cloud-Computing verwendet werden?
- Wie ist die Infrastruktur, in der das Modell in der Produktion laufen soll, beschaffen?
Der Aufbau des Datensatzes
Die Daten, die zur Repräsentation des Prozesses, der abgebildet werden soll, dienen, bestimmen grundlegend, wie gut das Modell ist. Zu Anfang sollten alle Daten, die observiert oder gesammelt werden können, für das Modell in Betracht gezogen und dann nach und nach selektiert und zusammengefasst werden. Nicht immer sind die benötigten Daten bereits vorhanden, was bedeuten kann, dass sie per Webscraping, Scraping von Dokumenten oder aus Datenbanken beschafft werden müssen. Daten aus verschiedenen Quellen müssen konsolidiert werden und in handhabbarem Format bereitgestellt werden.
- Gut überlegen, welche Beobachtungen und zugehörigen Variablen wichtig sind
- Woher kommen die Daten, wie werden sie am besten gespeichert, ist die Infrastruktur bereit?
- Beim Webscraping Berechtigungen zur Verwendung der Daten einholen
- Die Daten formatieren
- Sensible Informationen gegebenenfalls anonymisieren oder löschen
- Aus Sicherheitsgründen immer auf einer Kopie der Rohdaten arbeiten.
Datenexploration und Bereinigung
Wenn die Daten an einem Ort versammelt und in einem handhabbaren Format zusammengeführt wurden, kann mit der Exploration und dem Bereinigen des Datensatzes begonnen werden. Dies ist ein nicht zu unterschätzender Anteil des Gesamtprojektes, sowohl was den Zeitaufwand, als auch die Auswirkung auf das fertige Modell angeht. Bei der Exploration bedient man sich der Methoden der beschreibenden Statistik, um die Variablen, deren Wahrscheinlichkeitsverteilungen und deren Beziehungen untereinander kennenzulernen und zu verstehen. Gleichzeitig werden fehlende Werte substituiert, Ausreißer erklärt und behandelt und Fehler korrigiert.
- Überprüfung jeder Variablen auf Konsistenz und Richtigkeit
- Umgang mit fehlenden Werten finden
- Datentypen überprüfen und gegebenenfalls neu zuweisen
- Duplikate im Datensatz finden und entfernen
- Stimmen die Metainformationen (Domainwissen) mit den Daten überein?
- Visualisierung der Daten
- Welche Variablen gibt es und wie sind sie verteilt?
- Wie ist die Verteilung der Zielvariablen?
- Wie korrelieren die Variablen miteinander?
- Wie korrelieren die Variablen mit der Zielvariablen?
- Sehen die Ergebnisse anders aus, wenn Instanzen nach einem Attribut gruppiert werden (Simpson-Paradoxon)?
Die Auswahl und Konstruktion von Features
Ist der Datensatz in einem guten Zustand, werden die Attribute der Beobachtungen auf ihre Qualität und Wichtigkeit hin untersucht. Es werden Variablen, die eine starke Beziehung zur Zielvariablen haben, im Datensatz behalten, während andere, die wenig oder keine Relevanz für das Problem haben, entfernt werden. Manche Attribute, wie Datetime, können auseinandergenommen werden, weil ihre Teile möglicherweise mehr Information beinhalten, als das Ganze. So könnte der Wochentag eine wesentlichere Aussage machen, als das Datum, wenn es darum geht, die Länge einer Taxifahrt durch eine Großstadt vorherzusagen.
Beim Feature Engineering werden verschiedene „Ansichten“ auf den Sachverhalt modelliert, um den besten Betrachtungswinkel zu finden. Dafür werden unter anderem aus vorhandenen Variablen neue Features erzeugt, um Interaktionseffekte oder kurvige Beziehungen zwischen den unabhängigen und der abhängigen Variablen abzubilden.
- Auswahl der besten Features
- Dimensionsreduktion durch Kombination von Features, beispielsweise mit der Hilfe einer Hauptkomponentenanalyse
- Erzeugen neuer Features aus Interaktionen, Polynomialen Termen oder dem Hinzufügen neuer Variablen
- Testen von verschiedenen Kombinationen der Features
Feature Preprocessing
Im Preprocessing wird der Datensatz weiter optimiert. Je nach Aufgabenstellung, Lernalgorithmus und Struktur der Daten, kommen dabei verschiedene Methoden zum Einsatz.
Manche Lernalgorithmen haben bestimmte Ansprüche an das Format und die Skalierung der Daten. So sollten beispielsweise Daten, die in einem Neuronalen Netz verwendet werden, immer normalisiert sein. Regressionsalgorithmen haben, unter anderen, die Voraussetzung, dass die Multikollinearität im Datensatz gering ist, die Variablen unabhängig voneinander sind, die Beziehungen zwischen den unabhängigen Variablen und dem Ziel linear sind.
Bei einer Klassifizierung sollte der Datensatz ausgeglichen sein, das heißt, wenn eine Klasse stark unterrepräsentiert ist, sollten Maßnahmen ergriffen werden, damit diese Klassen vom Klassifikator dennoch gut gelernt werden können.
Oft kann es helfen, Variablen zu transformieren, um Beziehungen zwischen den unabhängigen und der abhängigen Variablen klarer herauszustellen. Für eine Abbildung nichtlinearer Beziehungen können Variablen beispielsweise logarithmiert werden.
- Standardisieren oder Normalisieren von Variablen
- Kategorische Variablen in Dummy-Variablen umwandeln
- Transformieren der Variablen
- Bei einer Klassifizierung eventuell unausgeglichene Klassen behandeln
- Multikorrelation reduzieren
Auswahl eines Lernalgorithmus und Hyperparameter Tuning
Bei der Wahl des Lernalgorithmus sollte man sich die Frage stellen, wie das Ergebnis präsentiert werden soll, als Funktion, als Baum oder als Satz von Regeln beispielsweise. Es sollte abgeklärt werden, ob es wichtig ist, die Ergebnisse leicht interpretieren zu können oder ob gute Vorhersagen im Vordergrund stehen. Bei vielen Anwendungen, bei denen Menschen direkt von den Entscheidungen eines Machine Learning Modells betroffen sind, ist es inzwischen rechtlich vorgeschrieben, dass die Modelle transparent sind, und im Nachhinein erklärt werden kann, warum eine Entscheidung so, und nicht anders getroffen wurde. Weitere Bedingungen, wie die Frage, ob ein schnelles Training oder ein geringer Platzbedarf wichtig sind und ob das Modell für Online Learning geeignet sein sollte, bestimmen die letztendliche Auswahl der Kandidaten. Diese werden anschließend auf einer Stichprobe des Datensatzes gegeneinander getestet, um dann den besten oder ein Ensemble der besten auszuwählen, und diese weiter zu optimieren.
Nach der Auswahl des Lernalgorithmus werden Kombinationen verschiedener Werte für die Hyperparameter, die für den vorliegenden Fall wichtig sind, in einer Kreuzvalidierung getestet. Sind genug Daten vorhanden, kann für das Hyperparameter-Tuning ein Development-Satz beiseitegelegt werden, ansonsten kann dafür der Trainingssatz verwendet werden.
- Vorauswahl mehrerer Lernalgorithmen, die in Hinblick auf den vorgesehenen Einsatz, Repräsentation der Ergebnisse und anderer wichtiger Faktoren in Frage kommen
- Testen mehrerer Algorithmen mit den voreingestellten Hyperparametern und Auswahl des vielversprechendsten Algorithmus
- Weiter mit dem besten Algorithmus oder einem Ensemble der besten Performer
- Hyperparameter Tuning mit Grid Search oder Randomized Search
Training, Evaluierung und Interpretation des Modells
Nach dem ersten Durchlauf von Training und Test werden die ersten Vorhersagen analysiert. Dies kann mithilfe von Lernkurven, Validierungskurven und manueller Auswertung der Vorhersagen geschehen. Um die Fehlerrate zu reduzieren, können verschiedene Herangehensweisen getestet, werden, so wie beispielsweise neue Zusammenstellungen von Features, andere Umgangsweisen mit fehlenden Werten, neue Transformationen. Es kann auch passieren, dass klar wird, dass wesentliche Informationen fehlen und dem Datensatz neue Attribute hinzugefügt werden müssen.
Bei einer Klassifizierung kann, je nachdem, wie die Kosten der gemachten Fehler eingeschätzt werden, versucht werden, die Fehlerart durch eine Änderung der Loss-Funktion oder Anpassung des Schwellenwerts zu beeinflussen.
- Verschiedene Feature-Sets testen und deren Performance vergleichen
- Testen des Models auf dem Test-Set, um Generalisierungsfehler feststellen
- Welche Features wurden vom Modell als wichtig erachtet?
- Beruhen die Vorhersagen des Modells auf sinnvollen Features?
- Ist der Performance-Score realistisch oder zu gut, um wahr zu sein (Data Leakage)?
- Lernkurven plotten
- Validierungskurven plotten
- Konfidenzintervalle berechnen
- Manuelle Fehleranalyse
- Bei einer Regression die Verteilung der Residuen plotten
- Wenn nötig, weitere Informationen beschaffen und zurück zum Feature Engineering und Preprocessing

Dokumentation
In einem Projektbericht werden alle Erkenntnisse zusammengefasst und visualisiert. Dazu gehören zum Beispiel die Feature Importances und Cumulative Feature Importances, Pairs Plots, ein Vergleich wahrer und vorhergesagter Werte, Lernkurven und ein Vergleich der Performance verschiedener Modelle und Konfidenzintervalle. Bei Regressionsanalysen kann zusätzlich ein Vorhersageintervall und bei Klassifizierungen die Wahrscheinlichkeiten für eine Klasse angeben werden.
Im Rahmen einer Präsentation sollten immer der Kontext, die Problemstellung und die Lösung für das Problem beschrieben werden. Dazu gehören auch neben den Ergebnissen auch eine Nennung der Ansätze, die nicht funktioniert haben und Ideen für fortführende Projekte bzw. Lessons learned aufschreiben und Maßnahmen in den Prozess aufnehmen.
- Univariate und bivariate Plots zur Illustration der Daten
- Beschreibung aller Annahmen, die getroffen wurden
- Beschreibung der Lösungsansätze und deren Ergebnisse
- Erklärung zu Ansätzen, die nicht funktioniert haben
- Visualisierungen der Ergebnisse
- Welche weiteren Erkenntnisse ergaben sich?
- Beschreiben, was in einem Folgeprojekt gemacht werden könnte
- Bei Standardanwendungen, wie Scikit-Learn oder Jupyter Notebooks nicht vergessen, die Versionen zu dokumentieren
Bereitstellung und Überwachung
Integration des Machine Learning Modells in die vorhandene Architektur. Planen von Monitoring und Management des Modells.
Die Performance eines Machine Learning Modells tendiert dazu, zu degradieren, sobald es in der Produktion eingesetzt wird. Dies liegt an einer Veränderung der Daten, die verwendet werden, um die Vorhersagen zu generieren. So kann sich beispielsweise das Verhalten von Kunden, je nach Saison, oder aus anderen Gründen, verändern und nicht mehr durch die Trainingsdaten ausreichend repräsentiert sein.
Wie häufig ein Modell upgedated werden sollte, hängt von der Art der Daten, die es verarbeitet ab. In sich schnell verändernden Umgebungen, wie der Internetsicherheit etwa, sollten konstant neue Daten trainiert werden. In anderen Gebieten, wie der Gesichtserkennung, bleiben die Inputs eher konstant und es muss seltener neu trainiert werden.
- Auswahl einer Data Science Platform
- Welche API Framework soll für den Zugriff auf das Modell verwendet werden?
- Wie soll Return on Investment des Modells gemessen und überwacht werden?
- Wie wird die Performance des Modells überwacht?
- Ist das Modell robust genug, um Angriffe (Adversarial Attacks) zu überstehen und wie können sie detektiert werden?
- Wie kann User Feedback implementiert werden?
- Wie wird das Veränderungsmanagement gehandhabt?
