Multikollinearität bedeutet, dass eine oder mehrere Variablen im Datensatz eine hohe Korrelation miteinander haben. Dadurch enthält der Datensatz redundante, und damit überflüssige, Informationen.
Bei Regressionsanalysen stellt die Multikollinearität insofern ein Problem dar, da hier vorausgesetzt wird, dass die Prädiktoren unabhängig voneinander sind. Dies ist eine Voraussetzung, damit die Beziehung zwischen Prädiktor und Target zu isoliert werden kann. Es wird der marginale Effekt einer Variablen auf das Target gemessen, indem diese verändert wird, während alle anderen konstant gehalten werden. Dies ist nicht mehr möglich, wenn die Veränderung einer Variablen die Veränderung einer anderen nach sich zieht, und die Koeffizienten der unabhängigen Variablen können nicht mehr eindeutig bestimmt werden.
Dies bedeutet eine sehr hohe Varianz (Standardfehler) bei der Schätzung der Koeffizienten, womit die Konfidenzintervalle sehr weit werden, und Signifikanztests erschwert werden.
Das resultierende Modell ist nicht robust und schon kleine Änderungen im Datensatz, beispielsweise durch das Hinzufügen oder Entfernen einer Variablen, oder die Wahl einer anderen Stichprobe, große Änderungen der geschätzten Koeffizienten nach sich ziehen können.
Die Vorhersagen aus Modellen mit kollinearen Variablen sind im Allgemeinen korrekt, wenn davon ausgegangen werden kann, dass bei neuen Daten die Kollinearität das gleiche Muster aufweist. Ist dies nicht der Fall, werden auch die Vorhersagen nicht mehr stimmen.
Weder bei der Klassifizierung noch bei der Regression können die Koeffizienten und damit die Feature Importance korrekt interpretiert werden. Selbst bei Random Forest, von dem es im Allgemeinen heißt, dass das Modell nicht sensitiv auf Multikollinearität sei, kann davon ausgegangen werden, dass die Feature Importances nicht stimmen.
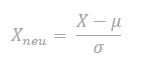
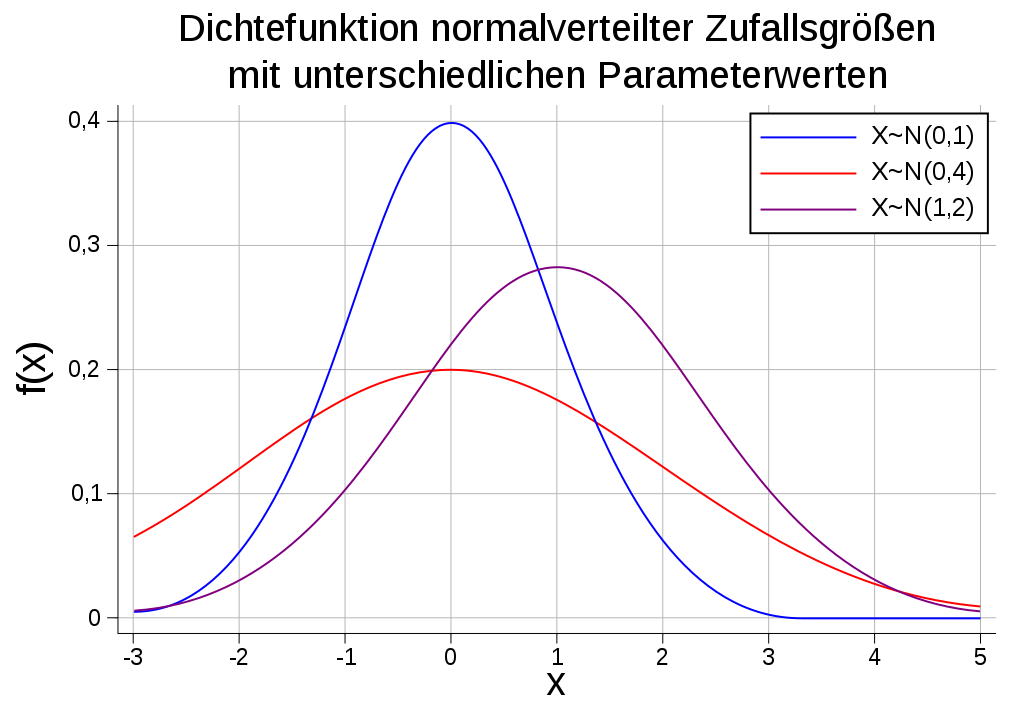
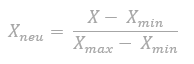

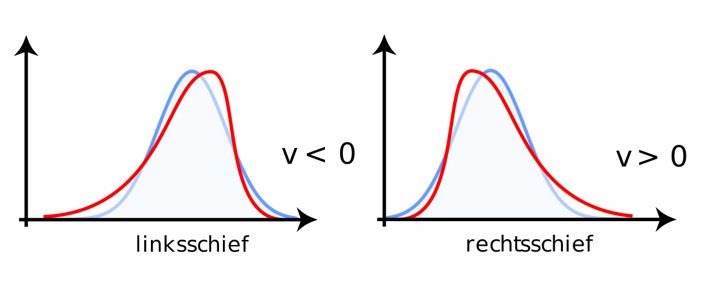
#/media/Datei:Linksschief.svg){kind=link}
