XAI
Transparenz für Machine Learning Modelle
Image by Jonny Lindner from Pixabay
Versteckte Risiken
Mitte der 90er entwickelten Forschergruppen des Center for Biomedical Informatics der University of Pittsburgh verschiedene Machine Learning Modelle mit dem Ziel, die Aufnahmeprozedur in Krankenhäusern zu vereinfachen. Das Modell sollte für die Entscheidung, ob ein Patient, der mit einer Pneumonie diagnostiziert wurde, ambulant oder stationär behandelt werden sollte, eine Grundlage geben.
Dafür sollte die Maschine ein Risikoprofil für Patienten erstellen, das sich aus der Wahrscheinlichkeit, dass der Patient an der Pneumonie sterben würde, ergab. Patienten, bei denen vorhergesagt wurde, dass die Krankheit ohne Komplikationen verlaufen würde, wurden mit einem geringen Risiko eingestuft. Sie konnten ambulant behandelt und nach Hause geschickt werden. Patienten mit einem hohen Risiko wurden sofort stationär aufgenommen und intensiv behandelt.
Für das Projekt wurden mehrere Modelle getestet und ein Multitask Neuronales Netz gewann mit dem höchsten Accuracy – Score auf den Daten. Doch bei der Analyse der einfacheren Modelle zeigte sich ein seltsames Muster. Patienten mit einer Geschichte von Asthma oder Herzkrankheiten hatte laut dieser Modelle ein geringeres Risiko, an der Pneumonie zu sterben. Praktisch bedeutete dies, dass diese Patienten, die neben einer Lungenentzündung auch an einer Herzkrankheit oder Asthma litten, vom Modell nach Hause geschickt würden.
Natürlich wäre diese Schlussfolgerung in der Praxis verheerend, wie jeder Arzt bestätigen würde. Bei der Besprechung des unlogischen Verhaltens des Modells fanden die am Projekt beteiligten Ärzte eine mögliche Erklärung: Patienten mit einer Vorerkrankung des Herzens oder Lunge wurden stets früher und intensiver behandelt. Zum einen wurden die Symptome früher entdeckt, da diese Patienten es gewohnt waren, auf Unregelmäßigkeiten im Brustbereich und der Atmung zu achten. Sie waren wahrscheinlich bereits in ärztlicher Behandlung und konnten so früher abklären, ob sie zur Untersuchung kommen sollten. Da es bei einer Infektion fundamental ist, schnell die Symptome zu bemerken und schnell in Behandlung zu kommen, hatten diese Patienten mit der Vorerkrankung also einen Vorteil. Zusätzlich werden Patienten mit dieser Vorgeschichte in der Regel sofort stationär aufgenommen und intensiv betreut, was ihre Chancen, die Pneumonie zu überleben, erheblich verbessert. Diesen Zusammenhang und den Effekt auf das Ergebnis hatte die Maschine korrekt erkannt. Nur war die Schlussfolgerung, dass Asthma oder Herzprobleme sich günstig auf eine Genesung auswirken, für diesen Anwendungsfall, in dem interveniert werden sollte, dem erwünschten Ergebnis entgegengesetzt.
Die Forscher gingen nun davon aus, dass das komplexere Neuronale Netz ähnliche Muster gelernt hatte. Das Problem aber war, dass sie es nicht mit Sicherheit wissen konnten, weil es keine Möglichkeit gab, in das Innere der Maschine zu blicken um die Abläufe und Logik zu analysieren. Und was, wenn es außer diesem noch weitere solcher Fallstricke im Modell gab? Unter diesen Voraussetzungen konnte das Neuronale Netz nicht weiter im Projekt verwendet werden und die Entwickler griffen auf das weniger akkurate, aber dafür sicherere Modell aus einer Logistic Regression zurück.
Hund oder Wolf?
Ein Beispiel aus einem Vortrag von Kasia Kulma zur Interpretationsmethode LIME zeigt, was passieren kann, wenn ein Modell, die falschen Attribute einer Beobachtung als wichtig einstuft. Die Forscher hatten ein Modell entwickelt, dass sehr gut darin war, auf Fotos zwischen von Wölfen und Huskies zu unterscheiden. Im Test jedoch hatte das Modell bei einigen Bildern große Schwierigkeiten, diese richtig zuzuordnen. Bei der Interpretation zeigte sich, dass die Bilder, die Wölfe zeigten, diese stets in einer Schneelandschaft abbildeten. Dies hatte zur Folge, dass das Modell Schnee im Hintergrund als wichtigstes Feature zur Wolfserkennung erkoren hatte. Das Ergebnis war ein sehr guter Schneedetektor, der allerdings leider keine Ahnung von Wölfen und Hunden hatte.
Was war bei den beiden Modellen schiefgegangen?
In beiden Fällen war die Ursache des Problems nicht im Lernalgorithmus, sondern in den Daten zu finden.
Im Risikomodell der Forscher aus Pittsburgh gab es eine Konfundierung. Es fehlte eine wichtige Variable, die die tatsächliche Ursache für die bessere Prognose für Pneumonie Patienten mit einer Vorgeschichte von Asthma oder Herzproblemen war. Diese Variable war die Handlungszeit, also wieviel Zeit verstrich, bis ein Patient eine medizinische Behandlung erfuhr. Dies ist, wie dieser Artikel der Pharmazeutischen Zeitung unterstreicht, einer der wesentlichen Faktoren bei der Einschätzung der Heilungschancen eines Patienten.
Beim Schneedetektor hatte das Modell selbstständig aus den gegebenen Bildern die Features extrahiert. Eines dieser Features war Schnee. Dieses Feature kam aufgrund einer zu kleinen oder verzerrten Stichprobe ausschließlich in Wolfsbildern vor, nicht aber auf Bildern mit Hunden und wurde deshalb als wichtiges Feature für die Wolfserkennung eingestuft, obwohl es in Wirklichkeit keinerlei Beziehung zum Ziel hatte.
Mit Hilfe dieser Erkenntnis konnte der Datensatz letztendlich so angepasst werden, dass wirklich die Tiere und deren Eigenschaften als wichtigste Features verwendet wurden und keine unwichtigen Features aus dem Hintergrund.
Warum ist das ein Problem für alle?
Unsere Gesellschaft hängt zunehmend von intelligenten Maschinen ab und Machine Learning Modelle werden immer häufiger in Umgebungen eingesetzt, in denen Menschen direkt von deren Ergebnissen beeinflusst werden.
In Justiz, Gesundheitswesen, Versicherungen und vielen weiteren Stellen des täglichen Lebens sind Machine Learning Modelle im Hintergrund am Wirken. Sie entscheiden, welche Emails in unserem Posteingang landen, welcher Partner zu uns passt und ob unser Kreditantrag bei der Bank angenommen oder abgelehnt wird.
Was die beiden obigen Beispiele zeigen, ist, wie ein scheinbar perfektes Modell Minen in der Black Box haben kann, die nicht mit Hilfe einer Metrik entdeckt werden können und die jederzeit getriggert werden könnten, wenn sie nicht frühzeitig entdeckt werden. Eine Metrik alleine ist also nur ein unvollständiges Maß für die Nützlichkeit eines Modells, denn sie kann zwar eine Aussage darüber machen, wie gut die Vorhersagen mit den wahren Werten übereinstimmen, jedoch kann sie keine Beschreibung der zugrundeliegenden Logik liefern. Sie kann uns sagen, wie gut ein Modell darin ist, Vorhersagen zu machen, doch sie kann uns nicht sagen, warum.
Im Augenblick ist es so, dass selbst die Entwickler eines komplexen Modells kaum mehr sagen können, wie dieses zu seinen Ergebnissen kam und auch ein hervorragender Score nicht ausreicht, um sicherzustellen, dass das Modell vertrauenswürdig ist.
Darüber hinaus können Probleme sogar verschlimmert werden, denn ein verzerrtes System kann auch ungewollte Mitkopplung verursachen. Das Modell lernt die falschen Muster nicht nur, sondern verstärkt diese auch.
Dies macht es unabdinglich, Machine Learning Modelle nicht nur auf höchste Genauigkeit zu trimmen, sondern sie auch zu verstehen.
In Zukunft werden Individuen und die Gesellschaft als Ganzes immer mehr von Entscheidungen, die mit Hilfe von Maschinen getroffen wurden, abhängen. Wenn diese Modelle Verzerrungen aufweisen, kann dies weitreichende und kritische Auswirkungen für alle Betroffenen bedeuten.
Und damit können Verzerrungen, Stereotypen und unfaire Schlussfolgerungen überall auftreten, von Machine Vision Systemen und Objekterkennung bis hin zur Spracherkennung (NLP) und sie können jederzeit unerwartete Konsequenzen für Individuen bereithalten.
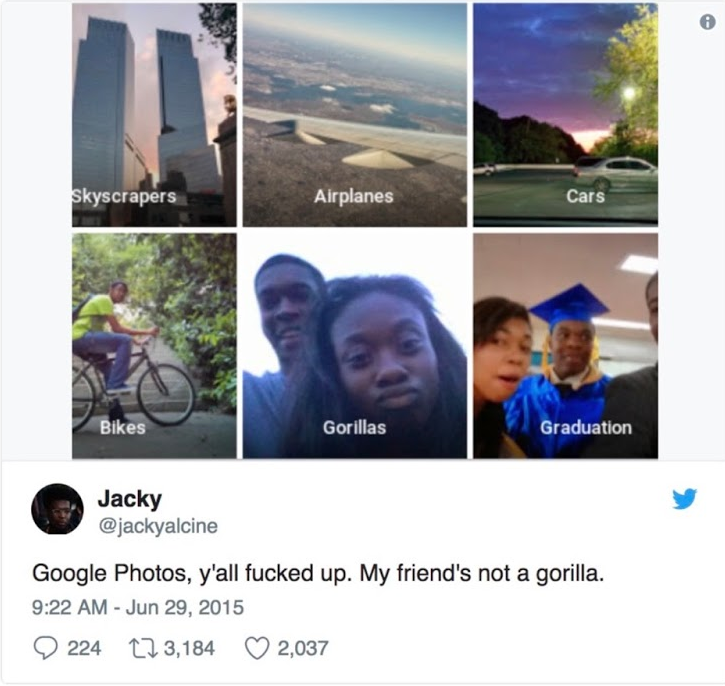
Dies kann bedeuten, dass ein System für die Klassifizierung von Bildern Menschen als Gorillas kategorisiert, Männer und Frauen unterschiedliche Kreditkartenlimits erhalten und online unterschiedliche Jobanzeigen präsentiert bekommen. Oder dass Frauen bei Bewerbungen benachteiligt werden. Es kann auch bedeuten, dass ein Mensch von dunklerer Hautfarbe alleine wegen dieses Merkmals länger im Gefängnis bleiben muss oder eine bestimmte Gegend nicht von Amazon beliefert wird und in einer sich selbstverstärkenden Schleife immer häufiger von der Polizei patrouilliert wird.
Die Folgen können gesellschaftlicher, ethischer, rechtlicher Natur sein. Oft werden sie als ungerecht und verletzend empfunden. Andere sind sicherheitsrelevant und könnten in den falschen Situationen fatale Auswirkungen haben.
Wie finde ich heraus, ob mein Datensatz heimliche Tendenzen hat?
Wenn man ein Problem beheben möchte, muss man erst einmal wissen, dass es da ist (Known unknowns vs. Unknown unknowns). Als die Forscher das Modell zum Patientenrisiko testeten, hatte es perfekte Scores. Der Datensatz war für die 90er ein perfekter Datensatz. Und trotzdem konnte sich ein Fehler einschleichen, der ohne die parallele Verwendung von transparenten Modellen für das gleiche Problem wahrscheinlich erst beim Einsatz, und wahrscheinlich mit fatalen Folgen, entdeckt worden wäre.
Wenn wir nicht wissen, was Modellintern vor sich geht und wie das System Attribute und Beziehungen zwischen diesen bewertet, kann es leicht passieren, dass das System Fehler machen, die nicht entdeckt werden. Die Accuracy ist hoch, das Modell kann gut generalisieren und dennoch ist ein Wurm im Modell. Die einzige Möglichkeit, diesen Wurm zu finden und das System zu korrigieren, ist, den Deckel der Black Box zu lüften und zu verstehen, was im Inneren abläuft.
Was kann man also tun, um die innere Logik einer Maschine erklären und verstehen zu können?

You never know what’s in the box. Unless you take a look.
Die Wurzel allen Übels
Wenn von Modell Bias gesprochen wird, so liegt dies nicht am Modell, das einfach ein Spiegel der Daten, auf denen es trainiert wurde, ist, sondern immer an den Daten. Dieser Bias ist auch nicht zu verwechseln mit einem Bias-Varianz-Problem des Lernalgorithmus, wo ein Bias durch eine Unteranpassung der Daten durch den Lernalgorithmus verursacht wird.

Für diese Verzerrung in Datensätzen gibt es sehr viele mögliche Gründe. Zum einen ist es möglich, dass die Stichprobe, die für das Training des Modells verwendet wird, nicht repräsentativ für die Population, auf der das Modell später angewandt werden soll, ist. Hierzu gehören auch Bias, die durch menschliche Stereotypen eingebracht werden können. Werden zum Beispiel auf Fotos, die klassifiziert werden sollen, Frauen ausschließlich in der Küche und Männer vor dem PC gezeigt, wird das Modell lernen, dass Frauen kochen und Männer rechnen. Es kann auch passieren, dass bei der Observation oder Messung Fehler auftreten, durch menschliche Kognition oder Bias oder Fehler in den Messinstrumenten wie eine fehlende Kalibrierung. Auch beim Versehen der Instanzen im Datensatz mit einem Label durch Menschen können Fehler passieren, die die Machine fraglos lernen wird. Ein sehr oft auftretendes Problem ist die Omitted-Variable-Bias. Dies bedeutet eine Verzerrung des Modells durch das Auslassen relevanter Variablen, die nicht kontrolliert werden können. Diese werden als Confounder bezeichnet. Ein Confounder hat eine Beziehung mit dem Target und auch einer oder mehrerer unabhängiger Variablen. Wenn der Confounder nicht im Datensatz ist, verfälscht dies Haupteffekte zwischen Prädiktoren und Ziel, da der Effekt des Confounders vom Modell anderen, im Datensatz vorhandenen Variablen zugewiesen wird. Wurde das Ziel des Modells nicht korrekt definiert und das Modell wird falsch eingesetzt, oder die Daten passen nicht zum Ziel, kann dies auch zu unvorhersehbaren Folgen führen.
Mögliche Quellen für Bias in Datensätzen
- Eine falsche Wahl der Stichprobe oder bei der Erhebung der Daten
- Systematische Fehler bei der Erhebung der Daten
- Fehler beim Labeln der Daten
- Confounder und Omitted-Variable-Bias
- Falscher Einsatz des Modells
Wie können wir nun mit diesem Problem umgehen, um es in unseren Modellen zu umgehen?
Wir interpretieren unsere Modelle!
Die Interpretation von Machine Learning Modellen
Bei der Interpretation eines Modells sollen Einsichten über sein Verhalten und seine Entscheidungen gewonnen werden, um herauszufinden, was intern beim Lernen geschieht und auf welche Informationen sich die gemachten Vorhersagen stützen. Praktisch bedeutet dies, herauszufinden, wie sich die einzelnen unabhängigen Variablen im Datensatz auf die abhängige Variable auswirken und wie die unabhängigen Variablen miteinander interagieren.
Eine Interpretation kann dabei helfen, Fehler oder Verzerrungen aufzudecken, die sonst möglicherweise unbemerkt bleiben würden, und sollte damit ein wesentlicher Bestandteil jedes Machine Learning Projektes sein.
Jede Variable hat einen Effekt auf das Ziel (Main Effekt), und manche Variablen haben gemeinsam einen unterschiedlichen Effekt auf das Ziel, als für sich genommen (Interaktionseffekt).
Machine Learning Modelle erkennen Korrelationen zwischen den Attributen und dem Ziel. Je stärker die Korrelation, desto wichtiger die Variable. Ist der Datensatz jedoch verzerrt, kann es passieren, dass einer Variablen Effekte zugesprochen werden, die diese nicht hat. Dies kann an einer Störvariablen liegen oder an Multikorrelation im Datensatz. Bei der Interpretation können diese Effekte angezeigt werden, um dann zu analysieren, ob sie tatsächlich der Realität sind oder ein Artefakt des Datensatzes.
Eine gute Interpretation, oder Erklärung, eines Modells liefert in erster Linie die Antwort auf die Frage nach dem Warum. Warum wurde meinem Kreditantrag bei der Bank nicht stattgegeben, warum hat diese Therapie beim Patienten nicht angeschlagen?
Sie einfach für den Menschen nachvollziehbar und erklärt neue Vorhersagen vollständig und konsistent.
Natürlich bedürfen nicht alle Modelle einer Erklärung. Wenn die Auswirkungen eines Fehlers keine große Tragweite haben, oder wenn die verwendeten Methoden bereits gut erforscht sind, kann darauf verzichtet werden.

Gute Gründe für die Interpretation von Modellen
Durch eine Interpretation können logische und systematische Fehler im Aufbau eines Modells offengelegt werden. Das Debugging wird vereinfacht, Feature Engineering, Preprocessing und künftige Datensammlungen können verbessert werden.
Es können die Sicherheit und Zuverlässigkeit des Modells nachgewiesen werden
Bevor ein Modell in der realen Welt genutzt wird, sollte immer nachgewiesen werden, dass es sicher ist und keine Entscheidungen trifft, die eine Gefahr darstellen könnten.
Wenn ein selbstfahrendes Auto Entscheidungen trifft, wollen wir sichergehen, dass es immer die richtige Entscheidung treffen wird. Wenn wir wissen, wie ein Fußgänger erkannt wird und wie dieser von anderen Objekten am Straßenrand unterschieden wird, kann eventuellen Fehlern vorgebeugt werden. (Allerdings werden wir hier noch vor andere Probleme gestellt werden, deren Lösung noch nicht klar ist. Siehe hier).
Vertrauen in das Modell wird geschaffen
Durch das Verstehen der versteckten Funktionalität wird das Vertrauen in die Ergebnisse eines Modells gestärkt. Wir möchten uns nicht blind auf das Modell als Quelle des Wissens verlassen, sondern die Möglichkeit haben, selbst dieses Wissen aus den Daten zu erlangen, wenn nötig.
Wissenschaftliche Entdeckungen werden gefördert
Sie kann helfen, tiefere Einsichten in die Natur eines Problems zu gewinnen und neue wissenschaftliche Erkenntnisse generieren.
Im Bild unten ist das BUN (Blood, Urea, Nitrogen) Level der Pneumonie-Patienten aus dem obigen Beispiel zu sehen. Die Grafik stammt aus einem GA2M Modell. Als die Statistiken der BUN Levels den Ärzten vorlagen, waren diese erstaunt, denn sie hatten bisher immer erst bei Patienten ab 50 Jahren diese Werte in Betracht gezogen, konnten nun aber sehen, dass das Level schon ab 40 Jahren anstieg. Niemand wusste, woher das Alter 50 als Grenze kam. Wie viele (falsche) traditionelle Weisheiten gibt es noch, die überprüft werden können?
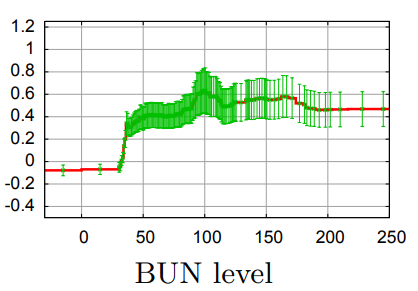
BUN Levels von Pneumonie Patienten. Quelle
Ethik und Fairness in der Gesellschaft werden verbessert
Die Ergebnisse eines Modells, das helfen soll, Entscheidungen zu treffen, die Auswirkungen auf Menschen haben, sollen nicht nur richtig sein, sondern auch anderen Bedingungen genügen. So ist es beispielsweise möglich, dass die Entscheidungen des Models zwar prinzipiell richtig sind, aber die Ergebnisse als unethisch oder ungerecht empfunden werden.
Ein Beispiel hierfür ist das Amazon Recruiting Tool, das Regeln gelernt hat, nachdem Bewerbungen, die das Wort „Women’s“ beinhalteten, schlechter bewertet wurden, als andere Bewerbungen, was dazu führte, dass Frauen, die sich bei Amazon beworben, benachteiligt wurden.
Rechtliche Gründe
Inzwischen gibt es auch Legale Gründe, offenzulegen, wie ein Modell seine Entscheidungen gefunden hat.
Die General Data Protection Regulation (GDPR), die am 25. Mai 2018 in Kraft trat, enthält eine Forderung nach Transparenz und dem Recht auf eine Begründung für die Entscheidung einer Institution.
Dazu gehören alle Entscheidungen, die einen großen Einfluss auf das Leben der Betroffenen haben können, wie Analysen über Kreditvergaben, Bewerbungsverfahren, Rückfallquoten (Strafrecht) oder Performance Bewertungen. Es wäre fast unmöglich, diesen Gesetzen ohne eine Interpretation der Modelle zu genügen.
Einfache und komplexe Modelle
Um die Beziehungen der Attribute eines Datensatzes abzubilden, gibt es viele Sorten von Lernalgorithmen zur Auswahl. Diese können beispielweise in ihrer Komplexität unterschieden werden. Einfache Lernalgorithmen produzieren lineare und monotone Antwortfunktionen. Sie sind leicht und direkt zu interpretieren und produzieren gute Vorhersagen. Komplexere Algorithmen können dagegen auch nichtlineare und nicht monotone Antwortfunktionen produzieren. Sie sind sehr flexibel und damit sehr genau, was aber leider dazu führt, dass sie auch komplett undurchschaubar sind. Sie können im Gegensatz zu den einfachen Modellen nicht mehr direkt interpretiert werden, sondern es müssen zusätzliche Techniken angewandt werden, um sie zu verstehen.
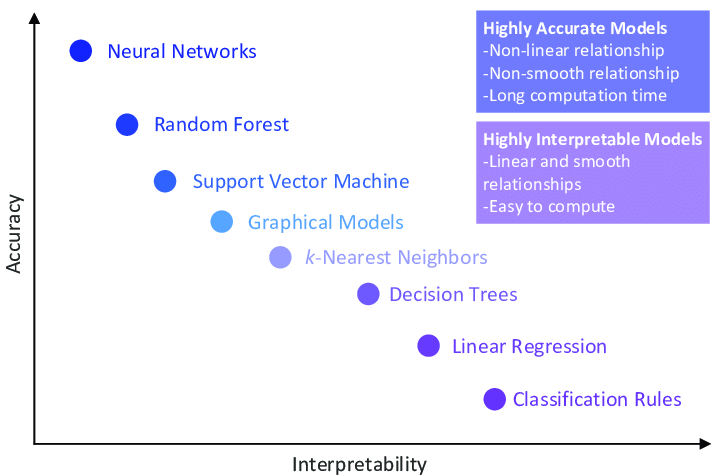
Trade-off zwischen der Komplexität bzw. Performance eines Modells und seiner Interpretationsfähigkeit. Quelle
Methoden der Interpretation
Ein guter Start
Ein guter Anfang für das tiefere Verständnis eines Machine Learning Modells ist immer die Data Exploration. Hier werden erste Einsichten und Erkenntnisse aus den Daten mit statistischen und visuellen Methoden gewonnen, Schlüssel-Variablen identifiziert werden und problematische Stellen im Datensatz aufgezeigt werden, wie zum Beispiel Ausreißer oder fehlende Werte. An dieser Stelle sollte der Datensatz auf Paradoxien und ähnliche Probleme hin untersucht werden.
Viele Fehler im Modell, sei es im Datensatz oder der Kombination Datensatz/Lernalgorithmus können nach dem ersten Trainings- und Testdurchlauf bei der Fehleranalyse aufgedeckt werden. Dazu gehören bei einer Regression beispielsweise die Analyse der Verteilung der Residuen. Zeigt sich hier ein System, kann davon ausgegangen werden, dass eine wichtige Variable im Modell fehlt.
Eine weitere Verzerrung der Ergebnisse kann durch zu starke Korrelationen zwischen den Prädiktoren verursacht werden. Dies ist problematisch, weil damit die Wichtigkeit einer Variablen falsch eingeschätzt werden könnte.
Die Verwendung einfacher Modelle
Viele Lernalgorithmen produzieren Modelle, die direkt interpretierbar sind. Aus ihnen kann direkt ersehen werden, wie wichtig jede Variable für die Vorhersage ist. Dazu gehören beispielsweise die Lineare Regression, Entscheidungsbäume, Logistische Regression, der Naive Bayes Classifier und K-Nearest Neighbors.
Eine weitere Algorithmen Klasse, die eine hohe Transparenz mit einer sehr guten Vorhersagekapazität kombiniert, sind Generalized Additive Models (Hastie und Tibshirani, 1986).
Oft ist ein einfaches, lineares Modell einem komplexeren Modell vorzuziehen, gerade wenn klar ist, dass die Entscheidungen des Modells hinterfragt werden.
Bei einem Projekt sollte man immer in Betracht ziehen, mit einem einfachen Modell zu beginnen und die Komplexität nur dann zu steigern, wenn die Performance für den gewünschten Anwendungsfall nicht ausreichen sollte.
Um die Performance eines linearen Modells zu verbessern, gibt es viele Möglichkeiten, die versucht werden können, bevor man auf ein komplexes Modell umsteigt. So kann eine Regularisierung eingesetzt werden oder es können im Feature Engineering Interaktions- und Polynomiale Terme dem Datensatz hinzugefügt werden, um komplexere Beziehungen abzubilden.
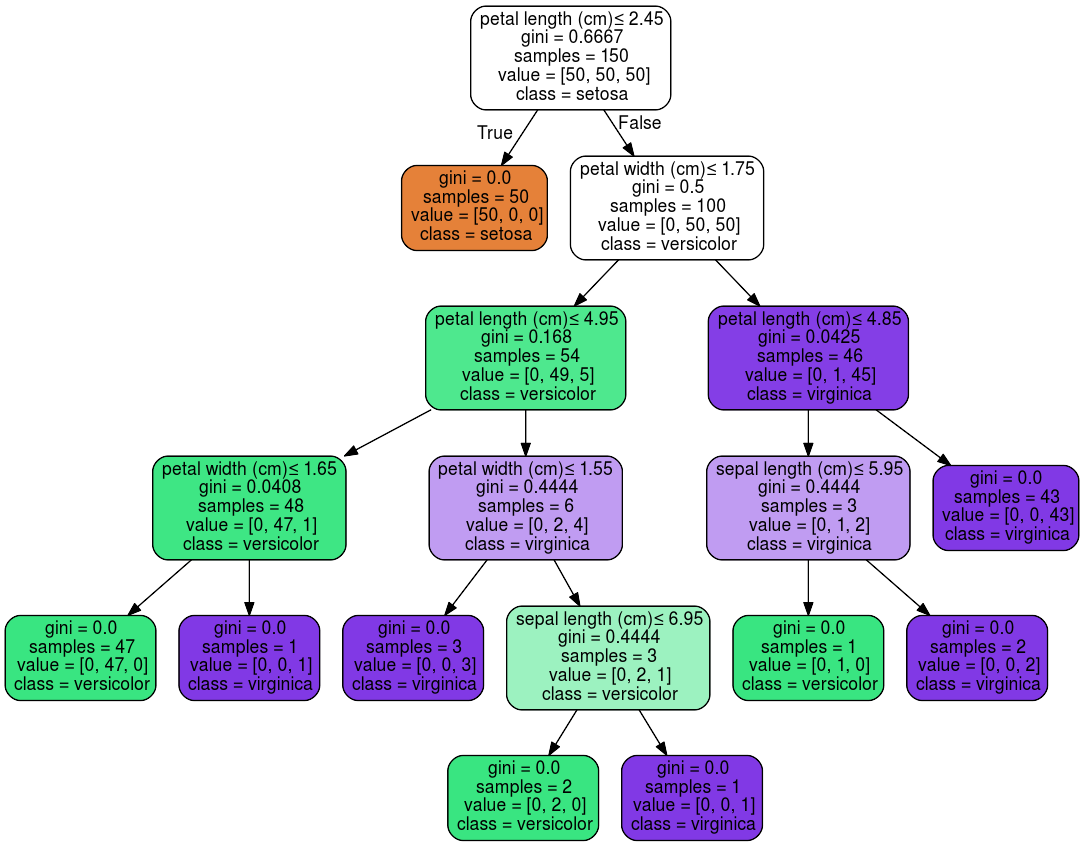
Visualisierung eines kleinen Entscheidungsbaumes aus Scikit-Learn für den berühmten Iris-Datensatz
Die modellunabhängige Interpretation
Soll ein komplexes Modell verwendet werden, weil es bei der Accuracy auf jede Stelle hinter dem Komma ankommt, gibt es andere Möglichkeiten, dem System seine Geheimnisse zu entlocken. Dafür wird es post-hoc mit Hilfe eines Modell-Agnostischen Verfahrens analysiert. Dieser Interpretationsmethoden sind flexibel und können auf jedes beliebige Modell angewendet werden.
Diese Verfahren unterscheiden sich zwischen lokalen und globalen Methoden. Die globalen Methoden erklären das Verhalten des Modells inklusive aller Beobachtungen, lokale Methoden erklären die Einflüsse der Variablen auf einzelne Beobachtungen. Lokale Erklärungen sind oft akkurater als globale Erklärungen.
Globale Surrogat-Modelle
Für die Verwendung eines Surrogats wird ein leicht zu interpretierendes Modell trainiert, um die Vorhersagen eines komplexen Modells zu approximieren. Dieses kann anschließend leicht interpretiert werden.
Dafür werden folgende Schritte ausgeführt:
- Komplexes Modell fitten und Vorhersagen machen
- Einfaches Modell wählen
- Das einfache Modell mit den Ergebnissen des komplexen Modells trainieren. Die Labels (Zielvariable) sind die Vorhersagen des komplexen Modells
- Berechnung der Performance des Surrogat-Modells
- Interpretation des Surrogat-Modells
Permutation Feature Importance (PFI)
Auch unter dem Namen Sensitivity Analysis bekannt. Um die Permutation Feature Importance zu berechnen, wird eine der unabhängigen Variablen verändert, während die anderen Variablen konstant gehalten werden. Dies kann durch eine einfache Durchmischung (Permutation) der Werte dieser Variablen erreicht werden. Das Modell mit der permutierten Variablen wird trainiert und evaluiert. Je stärker sich die Performance des Modells nach der Permutation verschlechtert, desto wichtiger ist diese Variable für die Vorhersage.
Die Methode läuft folgendermaßen ab: Das Model zunächst mit dem Originaldatensatz gefittet und ein Score wird berechnet. Im zweiten Schritt wird die im Fokus stehende Variable permutiert, der Datensatz wird gefittet und der neue Score ermittelt. Die PFI berechnet sich aus der Differenz der beiden Scores. Je höher die resultierende PFI, desto wichtiger ist die Variable im Modell.
Bibliothek für die Permutation Feature Importance in Python
https://scikit-learn.org/dev/modules/permutation_importance.html
Partial Dependence Plots (PDP)
Ein nützliches Tool für eine Interpretation von Kausalität in einem Modell ist das Partial Dependence Plot. Es wird verwendet, um den marginalen Effekt eines oder zweier Features auf den Output zu finden. Im Gegensatz zur Feature Importance, die nur eine Aussage darüber macht, welche Features für die Vorhersage die größte Rolle spielen, zeigen Partial Dependence Plots, wie eine Variable die Vorhersagen beeinflusst. Mit einem Partial Dependence Plot kann gezeigt werden, ob die Beziehung zwischen einem Feature und dem Target linear und monoton oder doch komplexer ist.
Nach dem Fitten des Modells wird der Wert einer Variablen wiederholt verändert. Bei numerischen Variablen wird die interessante Variable konstant gehalten, indem nacheinander alle Werte dieser Variablen für alle Instanzen gleichzeitig gesetzt werden. Die anderen Variablen bleiben unverändert. Mit dem veränderten Datensatz werden die Vorhersagen neu berechnet und gemittelt. Ist die interessante Variable kategorisch, wird nacheinander für alle Instanzen eine der Kategorien gesetzt. Bei einer Regression werden die Ergebnisse gemittelt, bei einer Klassifizierung die Wahrscheinlichkeiten der Klassenzugehörigkeit.
- Wähle ein Grid von Punkten in der Feature-Dimension, typischerweise die beobachteten Werte der Variablen im Trainingsdatensatz.
- Für jeden Punkt des Grids:
- Ersetze alle Werte mit dem Punkt des Grids
- Berechne die mittlere Antwort (Klassenwahrscheinlichkeit oder Wert der Regression)
Bei PDP ist zu beachten, dass Interaktionen die Interpretation erschweren können, wenn eine Variable von einer oder mehrerer anderer Variablen abhängt.
Es ist Voraussetzung, dass die Features, die konstant gehalten werden nicht mit denen, die untersucht werden, korrelieren. Ist dies nicht der Fall, kann es besser sein, Accumulated Local Effects (ALE) Plots zu verwenden.
Bibliotheken für Partial Dependence Plots
https://github.com/oracle/Skater/blob/master/skater/core/global_interpretation/partial_dependence.py
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.inspection
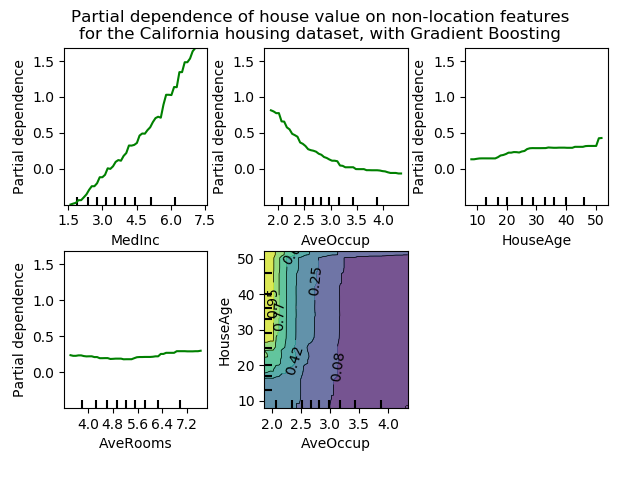
Beispiel aus dem California Housing Dataset in Scikit-Learn
Local Interpretable Model-Agnostic Explanations (LIME)
Bei LIME wird eine Permutation der Variablen zusammen mit einem Surrogat-Modell verwendet, um die Ergebnisse eines Black Box Modells lokal zu interpretieren.
Vorgehensweise für strukturierte Daten:
- Vorhersagen für alle Instanzen mit komplexem Modell machen
- Daten permutieren
- Den Abstand zwischen den permutierten und den unveränderten Instanzen berechnen
- Neue Vorhersagen mit dem komplexen Modell machen
- Testet verschiedene Kombination von Features, Kleinstmögliche Anzahl von Features, die die besten Vorhersagen mit den permutierten Daten machen
- Ein einfaches Modell auf die permutieren Daten mit den gleichen Features und Ähnlichkeits-Scores als Gewichten fitten
- Die Gewichte des einfachen Modells erklären das lokale Verhalten des komplexen Modells.
Die Punkte 2, 3, 5 und 6 können manuell angepasst werden, was den Algorithmus sehr flexibel macht.
Bei der Klassifizierung von Bildern wird ein Bild in interpretierbare Komponenten (Superpixels) aufgeteilt. Dann wird das Bild verändert, indem Teile der Superpixels nacheinander ausgeschaltet werden.
Bibliothek für LIME
https://github.com/marcotcr/lime
https://eli5.readthedocs.io/en/latest/index.html
Shapley Additive Explanations (SHAP)
SHAP ist eine konsistente, schnelle und deterministische Methode, um die Beiträge jeder Variablen der einzelnen Instanzen auf das Ergebnis zu extrahieren.
Mit diesem Verfahren lokale und globale Erklärungen erzeugt werden. Jede Observation erhält einen eigenen Satz von Shapley Werten, die kollektiven Shapley Werte können zeigen, wie jeder Prädiktor zur Vorhersage beiträgt.
Die Methode basiert auf Permutationen der Variablen in Kombination mit spieltheoretischen Ansätzen. Mit Hilfe des Shapley-Wertes wird der marginale Effekt jeder Variablen bewertet. Dieser sagt aus, wie sich eine abhängige Variable ändert, wenn eine spezifische unabhängige Variable verändert wird, während alle Kovariablen konstant gehalten werden.
Ein Spieler kann für den Wert einer einzelnen Variablen stehen, oder aber für eine Gruppe von Variablenwerten. Bei Bildern werden beispielweise mehrere Pixel zu einem Spieler gruppiert. Ein Modell ist eine Koalition aller Spieler. Der Gewinn berechnet sich aus der Vorhersage für diese Instanz abzüglich der mittleren Vorhersage aller Instanzen.
Für jede Instanz des Datensatzes werden die Werte mit denen einer zufällig gezogenen, anderen Instanz aus dem Datensatz nacheinander ersetzt und die Vorhersage berechnet, dazu gehören auch Kombinationen, bei denen die Werte minimiert werden.
Diese Berechnung wird wiederholt für alle möglichen Koalitionen durchgeführt und die Ergebnisse am Ende gemittelt. Der Shapley Value ist der Mittelwert aller marginalen Beiträge aller möglicher Koalitionen.
Um die Rechenzeit gering zu halten, können die Beiträge nur für einige wenige Proben berechnet werden.
Libraries für SHAP
https://shap.readthedocs.io/en/latest/
Bei XGBoost, CatBoost und LightGBM ist SHAP bereits integriert.
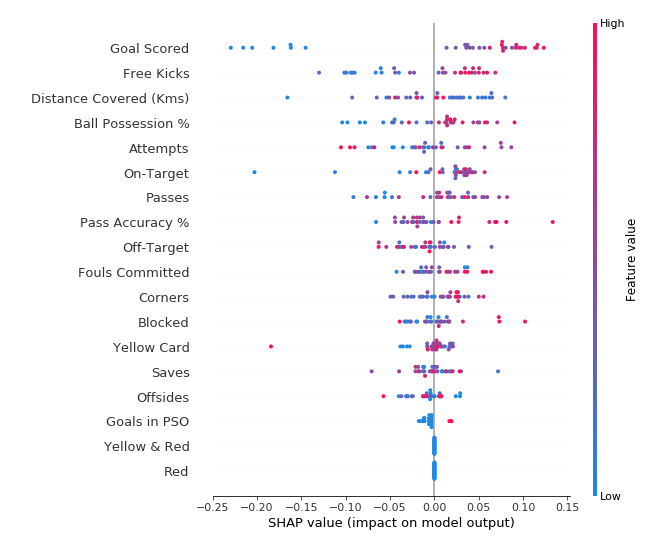
Beispiel für die Auswertung von Fußballspielen aus Kaggle von hier.
Lesen des Plots:
- Jeder Punkt steht für eine Observation
- Die Variablen sind nach Wichtigkeit sortiert, beginnend mit der wichtigsten Variablen von oben nach untern
- Die horizontale Lage auf der x-Achse zeigt die Stärke des Effekts auf die Vorhersage, positive Werte sind positiv mit dem Ergebnis korreliert, negative Werte haben eine negative Korrelation mit y
- Die Farben zeigen die Höhe des Wertes der Variablen der jeweiligen Instanz an
Wie gehe ich mit dem Bias in meinem Datensatz um?
Die beste Methode, sicherzustellen, dass ein Modell die richtigen Antworten auf meine Fragen gibt, ist, es sehr gut zu kennen. Und dies bedeutet, den Datensatz vollständig zu verstehen. Deswegen ist eine gute Exploration der Daten mit statistischen Methoden und Visualisierungstechniken immer der erste Schritt. Diese können den Datensatz illustrieren, das Verhalten und die Beziehungen von Variablen aufzeigen.
Bei jeder darauffolgenden Entscheidung sollte alle möglichen Konsequenzen bedacht und auch getestet werden. Ob Ausreißer behandelt werden, die Variablen normalisiert oder transformiert werden, oder neue dem Datensatz neue Features hinzugefügt werden, immer sollten die Auswirkungen klar sein. Die Auswahl der Metrik, des Lernalgorithmus und seiner Hyperparameter sollte sorgfältig bedacht sein. Jeder Algorithmus hat unterschiedliche Anforderungen an den Datensatz, jede Metrik misst etwas anderes. Manche sind empfindlich gegen Ausreißer, manche übersehen eine Unausgeglichenheit in den Klassen. Gibt es Unsicherheiten, welcher Weg am besten einzuschlagen ist, hilft es, zu experimentieren.
Nach den ersten Trainings- und Testdurchläufen ist eine gute Fehleranalyse unabdingbar, um mögliche Irrungen aufzudecken, wie beispielsweise fehlende Variablen oder redundante Informationen. Für jeden Fehler, den das Modell macht, können Hypothese aufgestellt und getestet werden. Wichtige Schritte im Projekt sollten immer mit einem Domainexperten besprochen werden und Ergebnisse gemeinsam mit diesem analysiert werden.
Möglichkeiten für die Verringerung von Bias im Datensatz
Stichproben-Bias: Mehr Daten sammeln und dabei versuchen, von allen Variationen mehrere Beispiele zu haben. Im Beispiel der Wolferkennung wäre dies, Bilder mit und ohne Schnee, zusammen mit Wölfen und Hunden, in den Datensatz aufzunehmen. Ist dies nicht möglich, kann ein Resampling versucht werden. Ein Oversampling der seltenen Instanzen oder Untersampling der häufigeren Instanzen könnte dem Modell helfen.
Eine weitere Möglichkeit wäre es, die unwesentliche Variable kontrollieren, das heißt, diese konstant zu halten. Im Wolfsbeispiel würde dies bedeuten, in allen Bildern Schnee zu haben, oder in keinem der Bilder.
Systematische Fehler: Messgeräte überprüfen und kalibrieren, Randomisieren
Fehler beim Labeln: Den Datensatz von verschiedenen Menschen labeln lassen.
Confounder und Omitted-Variable-Bias: Die wichtigen Variablen in den Datensatz inkludieren. Diese können oft schon durch eine gute Recherche vor der Datenaufnahme identifiziert werden. Leider ist dies in der Praxis nicht immer möglich, sei es aus ethischen oder praktischen Gründen. Es wäre im Beispiel der Pneumonie-Risiko-Studie, gut für das Modell, Instanzen zu erhalten, in denen Asthma Patienten nach Hause geschickt würden, was natürlich unmöglich ist.
Gerade im Gesundheitswesen ist es schwierig, gute Daten außerhalb des Rahmens einer Studie zu bekommen, meistens muss sich der Entwickler mit kleinen und unordentlichen Datensätzen zufriedengeben. Ist es unmöglich, die Variable zu finden und in den Datensatz zu integrieren, könnte die Verwendung einer Proxy-Variablen funktionieren, um die Effekte der anderen Variablen besser einordnen zu können.
Einsatz des Modells genau definieren: Vor der Entwicklung des Modells genau abklären, wofür es gedacht ist. Welche Fragen soll es beantworten? Was wird mit den Ergebnissen gemacht? Soll in den abgebildeten Prozess interveniert werden oder ist das Ergebnis rein informativ? Das Risikomodell für Pneumonie sagte nicht den Krankenhausaufenthalt, sondern das Risiko zu sterben, voraus. Dies war für den vorhergesehen Zweck ungünstig, da es die falsche Frage beantwortete. Für einen Versicherer dagegen wäre das Modell, so, wie es ist, absolut verwendbar, da es das Risiko eines Patienten, zu sterben, korrekt vorhersagte. Es ist also immer sinnvoll, sich vor dem Aufbau eines Modells genau zu überlegen, was man wirklich wissen will und was man mit den Informationen, die es liefert, anfangen möchte.
Unglückliche Variablen: Variablen, die dem Datensatz Information hinzufügen, deren Verwendung als ungerecht oder ethisch und moralisch nicht tragbar empfunden wird.
Um diesem Problem zu begegnen, sollten die unliebsamen Variablen nie einfach aus dem Datensatz entfernt werden, denn sie beinhalten eine wichtige Information. Zudem befinden sich meistens andere Variablen im Datensatz, die indirekt die gleiche Aussage treffen. Zum Beispiel könnte man in den USA nicht nur von der Variablen „Race”, sondern oft auch vom Namen oder von der Anschrift eines Menschen auf seine Ethnizität schließen. Oft kann die Postleitzahl des Wohnortes eines Menschen Informationen über soziologische, kulturelle und finanzielle Umstände beinhalten.
In jedem Datensatz gibt es diese latenten Attribute, die ähnliche Rückschlüsse zulassen, wie das Hauptattribut. Es ist also besser, die vermeintlich störende Variable im Datensatz zu belassen, um ihren Effekt zu analysieren und sich dann zu überlegen, wie man damit umgehen möchte. Wenn diese Variable fehlt, weil sie vor dem Training entfernt wurde, ist der gleiche Effekt oft dennoch im Ergebnis, aber nicht mehr aufzuspüren.
Bei all dem sollte man nicht vergessen, dass, unter der Voraussetzung, dass das Modell korrekt aufgebaut wurde, es ein Abbild der Realität ist.
Korrelation und Kausalität im Machine Learning
Bei der Evaluierung und Interpretation von Machine Learning Modellen wird oft fälschlicherweise angenommen, dass die entdeckten Beziehungen zwischen den Variablen kausaler Natur sind. Aber – Korrelation impliziert keine Kausalität. Eine Assoziation, oder Korrelation, zwischen zwei oder mehr Variablen kann einfach bedeuten, dass diese gemeinsam variieren. Sie bedeutet nicht, dass die Änderungen der einen Variablen Änderungen der anderen Variablen verursachen. Um gute Vorhersagen zu machen, ist es meistens ausreichend, starke Beziehungen zwischen den Variablen zu finden. Ob diese korrelativ oder kausal sind, ist damit nicht wirklich wichtig.
Soll das Modell und seine gelernten Beziehungen jedoch dazu verwendet werden, Änderungen im Ergebnis herbeizuführen, kann es durchaus sinnvoll sein, sich zu überlegen, wie das Ziel tatsächlich beeinflusst wird. Denn damit absichtliche Änderungen einer Variablen die Zielvariable beeinflussen, muss es eine kausale Beziehung zwischen den beiden geben. Leider gibt es bislang keine statistischen Tests, mit deren Hilfe Kausalität determiniert werden kann.
Wie kommt es, dass Variablen miteinander korreliert sind, aber keine kausale Beziehung miteinander haben?
Ein häufiger Grund sind Störvariablen (Confounder), die eine Scheinkorrelation verursachen (Spurious Correlation). Die Ursache dafür, dass Patienten mit einer Lungenentzündung ein geringeres Risiko hatten, war natürlich nicht das Asthma, sondern die Früherkennung und sofortige Behandlung der Lungenentzündung. In diesem Fall war also das schnelle Handeln der Confounder.
Erst durch Hinzunahme des menschlichen Verständnisses von Ursache und Wirkung konnte der Fehler im Modell behoben werden. Wäre ein Machine Learning Modell in der Lage, Kausalität richtig einzuordnen, wäre der Fehler nicht passiert.
Solange dies nicht der Fall ist, ist es immer sicherer, jedes Modell genau zu untersuchen, um kausale Zusammenhänge zu entdecken und zwischen Kausalität und Korrelation zu unterscheiden.
Eine Hilfe dafür können die Bradford-Hill-Kriterien für Kausalität sein.
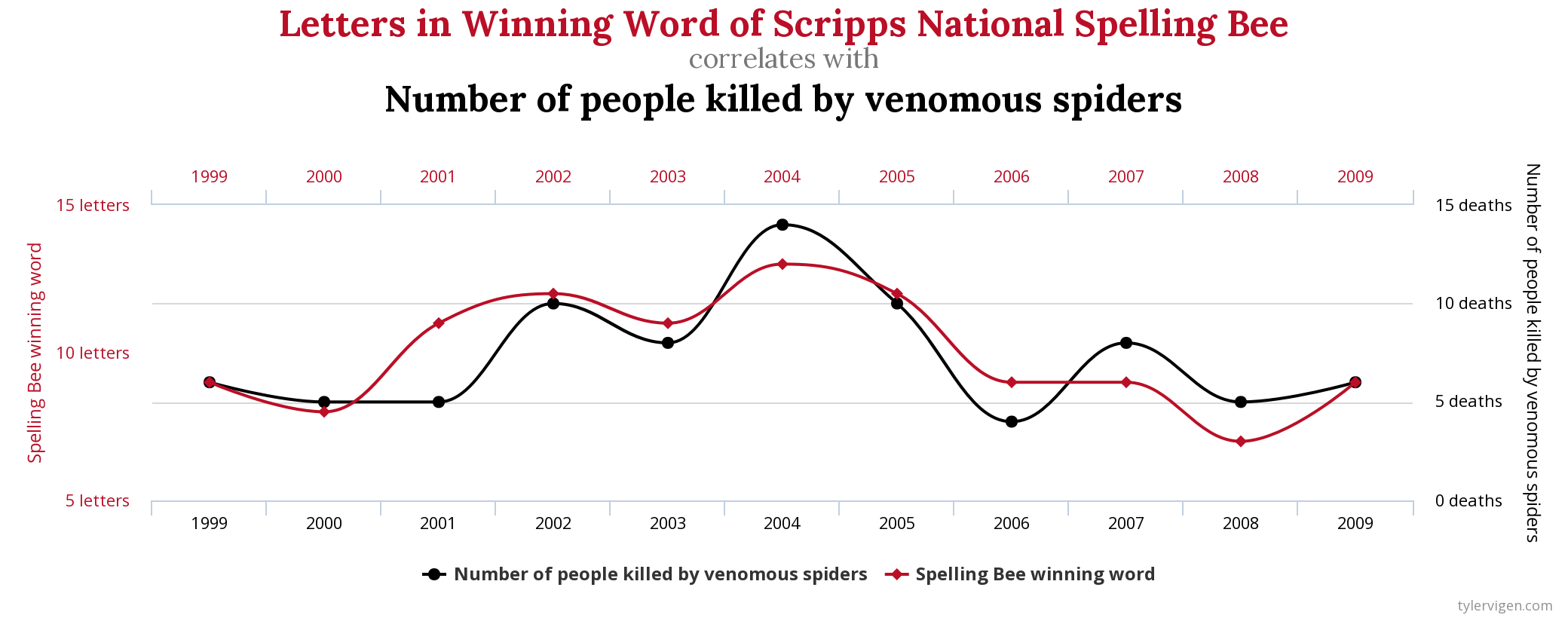
Eine verdächtige Korrelation aus http://tylervigen.com/spurious-correlations
Schluss
Es wurde besprochen, dass es für die Güte und die Nützlichkeit eines Modells einen großen Vorteil bedeuten kann, wenn Entwickler und auch Anwender verstehen, wie es zu seinen Ergebnissen kommt. Da man nie von vorneherein wissen kann, ob ein Datensatz, und damit das auf diesem trainierte Modell, verzerrt ist, hilft es nur, dieses fertigzustellen und dann zu analysieren. Mit einfachen Modellen ist es einfacher zu verstehen, welcher Logik sie folgen. Je komplexer ein Modell ist, desto schwieriger wird dies und man ist auf die Hilfe von Verfahren angewiesen, die lokale und globale Erklärungen für Vorhersagen geben können. Das Verständnis eines Modells kann helfen, Probleme aufzudecken, die nicht antizipiert worden waren um damit zu vermeiden, dass man im Blindflug unterwegs ist.